Interesul pentru viziunea computerizată a fost unul dintre primele în domeniu inteligență artificialăîmpreună cu sarcini precum demonstrarea automată a teoremelor și jocurile mintale. Chiar și arhitectura primului artificial Retea neurala- perceptron - a fost propus de Frank Rosenblatt, pe baza analogiei cu retina, iar studiul acesteia a fost realizat pe exemplul problemei recunoașterii imaginii caracterelor.
Semnificația problemei vederii nu a fost niciodată pusă la îndoială, dar, în același timp, complexitatea acesteia a fost semnificativ subestimată. De exemplu, cazul în care, în 1966, unul dintre fondatorii domeniului inteligenței artificiale, Marvin Minsky, nici măcar nu avea de gând să rezolve el însuși problema vederii artificiale, ci a instruit un student să o facă în vara următoare, a devenit legendar în exponenţialitatea acestuia. În același timp, a fost alocat mult mai mult timp pentru a crea un program care să joace la nivelul unui mare maestru în șah. Cu toate acestea, acum este evident că crearea unui program care bate o persoană în șah este mai ușoară decât crearea unui sistem de control adaptiv cu un subsistem de viziune computerizată care ar putea pur și simplu rearanja piesele de șah pe o tablă reală arbitrară.
Progresul în domeniul viziunii computerizate este determinat de doi factori: dezvoltarea teoriei, metodelor și dezvoltarea hardware-ului. Pentru o lungă perioadă de timp, teoria și cercetarea academică au fost înaintea curbei uz practic sisteme de viziune computerizată. Este posibil să se evidențieze în mod condiționat un număr de etape în dezvoltarea teoriei.
- Până în anii 1970 s-a format principalul aparat conceptual în domeniul prelucrării imaginilor, care stă la baza studiului problemelor de vedere. Au fost identificate, de asemenea, principalele sarcini specifice viziunii artificiale, legate de evaluarea parametrilor fizici ai scenei (rama, viteze de mișcare, reflectivitate a suprafețelor etc.) din imagini, deși o serie dintre aceste sarcini erau încă luate în considerare într-un mod foarte formulare simplificată pentru „lumea cuburilor de jucărie”.
- În anii '80, s-a format o teorie a nivelurilor de reprezentare a imaginilor în metodele de analiză a acestora. Cartea lui David Marr Vision. Abordarea informațională a studiului reprezentării și procesării imaginilor vizuale.
- Până în anii 1990, s-a format o idee sistematică a abordărilor pentru rezolvarea principalelor probleme, acum clasice, ale vederii mecanice.
- De la mijlocul anilor '90, a existat o tranziție către crearea și studiul sistemelor de viziune computerizată la scară largă concepute să funcționeze în diferite condiții naturale.
- Etapa actuală este cea mai interesantă în dezvoltarea metodelor de construire automată a reprezentărilor de imagini în sistemele de recunoaștere a imaginilor și viziune pe computer bazate pe principiile învățării automate.
În același timp, aplicațiile erau limitate de resursele de calcul. Într-adevăr, pentru a realiza chiar și cea mai simplă procesare a imaginii, trebuie să-i vizualizați toți pixelii cel puțin o dată (și de obicei de mai multe ori). Pentru a face acest lucru, trebuie să efectuați cel puțin sute de mii de operații pe secundă, ceea ce pentru o lungă perioadă de timp a fost imposibil și a necesitat simplificări.
De exemplu, pentru recunoașterea automată a detaliilor în industrie, ar putea fi utilizată o bandă transportoare neagră, eliminând necesitatea de a separa obiectul de fundal, sau scanarea unui obiect în mișcare cu o linie de fotodiode cu iluminare specială, care deja la nivelul de formarea semnalului a asigurat selectarea caracteristicilor invariante pentru recunoaștere fără utilizarea unor metode complexe de analiză a informațiilor. În sistemele optoelectronice pentru urmărirea și recunoașterea țintelor, s-au folosit șabloane fizice, permițând „hardware-ului” să efectueze o filtrare consistentă. Unele dintre aceste soluții erau ingenioase din punct de vedere ingineresc, dar erau aplicabile numai problemelor cu incertitudine a priori scăzută și, prin urmare, aveau, în special, o portabilitate slabă la probleme noi.
Deloc surprinzător, anii 1970 au văzut, de asemenea, vârful interesului pentru calcularea optică în procesarea imaginilor. Ei au făcut posibil set mic metode (în principal corelaționale) cu proprietăți de invarianță limitate, dar într-un mod foarte eficient.
Treptat, datorită creșterii performanței procesorului (precum și dezvoltării camerelor video digitale), situația s-a schimbat. Depășirea pragului de performanță necesar pentru a efectua procesarea utilă a imaginii într-un timp rezonabil a deschis calea pentru o avalanșă de aplicații de viziune computerizată. Cu toate acestea, trebuie subliniat imediat că această tranziție nu a fost instantanee și continuă până în zilele noastre.
În primul rând, algoritmi de procesare a imaginilor aplicabili în general au devenit disponibili pentru procesoarele speciale - procesoare de semnal digital (DSP) și circuite integrate logice programabile în câmp (FPGA), care sunt adesea partajate și sunt încă utilizate pe scară largă în sistemele de bord și industriale.

Cu toate acestea, metodele de viziune computerizată au fost cu adevărat utilizate pe scară largă abia în urmă cu mai puțin de zece ani, odată cu atingerea unui nivel adecvat de performanță a procesorului în personal și calculatoare mobile. Astfel, în ceea ce privește aplicarea practică a sistemelor de viziune computerizată, au trecut o serie de etape: etapa soluționării individuale (atât din punct de vedere hardware, cât și din punct de vedere al algoritmilor) a sarcinilor specifice; stadiu de aplicare în domenii profesionale (în special în industrie și apărare) folosind procesoare speciale, sisteme de imagistică specializate și algoritmi menționați să funcționeze în condiții de incertitudine a priori scăzută, totuși, aceste soluții au permis scalarea; și stadiul aplicării în masă.
După cum puteți vedea, sistemul de viziune automată include următoarele componente principale:

Cea mai răspândită utilizare este realizată de sistemele de viziune artificială care folosesc camere standard și computere ca primele două componente (termenul de „viziune computerizată” este mai potrivit pentru astfel de sisteme, deși nu există o separare clară între conceptele de viziune artificială și viziune pe computer. ). Cu toate acestea, firește, alte sisteme de viziune artificială nu sunt mai puțin importante. Este alegerea metodelor de imagistică „non-standard” (inclusiv utilizarea unor intervale spectrale, altele decât cele vizibile, radiații coerente, iluminare structurată, dispozitive hiperspectrale, timp de zbor, camere omnidirecționale și de mare viteză, telescoape și microscoape etc. .) care extinde semnificativ capacitățile sistemelor de viziune artificială . În timp ce sistemele de viziune artificială sunt semnificativ inferioare vederii umane în ceea ce privește capacitățile de suport algoritmic, ele sunt semnificativ superioare în ceea ce privește posibilitățile de obținere a informațiilor despre obiectele observate. Cu toate acestea, problemele formării imaginilor constituie o zonă independentă, iar metodele de lucru cu imagini obținute folosind diferiți senzori sunt atât de diverse încât analiza lor depășește scopul acestui articol. În acest sens, ne vom limita la o revizuire a sistemelor de viziune computerizată care utilizează camere convenționale.

Aplicație în robotică
Robotica este un domeniu tradițional de aplicare pentru viziunea artificială. Cu toate acestea, cea mai mare parte a flotei de roboți a căzut pentru o lungă perioadă de timp în industrie, unde detectarea roboților nu era de prisos, dar datorită condițiilor bine controlate (nedeterminism scăzut al mediului), soluțiile foarte specializate s-au dovedit a fi posibil, inclusiv pentru sarcinile de viziune artificială. În plus, aplicațiile industriale au permis utilizarea echipamentelor scumpe, inclusiv a sistemelor optice și de calcul.
În acest sens, este semnificativ (deși nu numai legat de sistemele de viziune computerizată) faptul că ponderea parcului de roboti atribuită roboților industriali a devenit mai mică de 50% abia la începutul anilor 2000. Robotica concepută pentru consumatorul de masă a început să se dezvolte. Pentru roboții de uz casnic, spre deosebire de cei industriali, costul este critic, precum și timpul. durata de viata a bateriei, ceea ce presupune utilizarea sistemelor de procesoare mobile și încorporate. În același timp, astfel de roboți trebuie să funcționeze în medii nedeterministe. De exemplu, în industrie pentru o lungă perioadă de timp (și până în prezent) marcajele fotogrammetrice lipite pe obiectele de observare sau plăci de calibrare au fost folosite pentru a rezolva problemele de determinare a parametrilor interni și orientării exterioare a camerelor. Desigur, necesitatea de a lipi astfel de etichete de utilizator pe articolele de interior ar înrăutăți semnificativ calitățile de consum ale roboților de uz casnic. Deloc surprinzător, piața roboților de uz casnic aștepta ca un anumit nivel de tehnologie să înceapă dezvoltarea rapidă, ceea ce s-a întâmplat la sfârșitul anilor 90.
Punctul de plecare al acestui eveniment poate fi lansarea primei versiuni a robotului AIBO (Sony), care, în ciuda relativ preț mare(2500 USD), a fost la mare căutare. Primul lot de acești roboți în valoare de 5.000 de exemplare a fost vândut pe Internet în 20 de minute, al doilea lot (tot în 1999) în 17 secunde, iar apoi rata de vânzări a fost de aproximativ 20.000 de exemplare pe an.
Tot la sfârșitul anilor 90 au apărut în producția de masă dispozitive care ar putea fi numite roboți de uz casnic în sensul deplin al cuvântului. Cei mai tipici roboți autonomi de uz casnic sunt aspiratoarele robotizate. Primul model lansat în 2002 de iRobot a fost Roomba. Apoi au existat aspiratoare robot produse de LG Electronics, Samsung etc. Până în 2008, vânzările totale de aspiratoare robot în lume se ridicau la peste jumătate de milion de exemplare pe an.
Este semnificativ faptul că primele aspiratoare robotizate echipate cu sisteme de viziune computerizată au apărut abia în 2006. Până la acest moment, utilizarea procesoare mobile tipul familiei ARM cu o frecvență de 200 MHz a făcut posibilă realizarea unei comparații a imaginilor scenelor tridimensionale din interior pe baza descriptorilor invarianți puncte cheieîn scopul localizării senzoriale a robotului cu o frecvenţă de aproximativ 5 cadre/s. Utilizarea vederii pentru a determina locația robotului a devenit justificată din punct de vedere economic, deși până de curând producătorii preferau să folosească sonarele în aceste scopuri.
Îmbunătățirea în continuare a performanței procesoarelor mobile ne permite să stabilim noi provocări pentru sistemele de viziune computerizată în roboții de uz casnic, al căror număr este deja vândut în întreaga lume în milioane de exemplare pe an. Pe lângă sarcinile de navigare, roboții destinați uzului personal pot fi solicitați pentru a rezolva problemele de recunoaștere a oamenilor și a emoțiilor acestora după chipuri, recunoașterea gesturilor, obiecte de mobilier, inclusiv tacâmuri și ustensile, haine, animale de companie etc., în funcție de tipul sarcinilor. rezolvate de robot. Multe dintre aceste sarcini sunt departe de a fi solutie completași sunt promițătoare din punct de vedere inovator.

Astfel, robotica modernă necesită rezolvarea unei game largi de probleme de vedere computerizată, inclusiv, în special:
- un set de sarcini legate de orientarea în spațiul exterior (de exemplu, sarcina de localizare și cartografiere simultană - Simultaneous Localization and Mapping, SLAM), determinarea distanțelor față de obiecte etc.;
- sarcini de recunoaștere a diferitelor obiecte și de interpretare a scenelor în general;
- sarcini de detectare a oamenilor, recunoaștere a fețelor acestora și analiza emoțiilor.
Sisteme de asistență pentru șofer
Pe lângă roboții de uz casnic, metodele de viziune computerizată și-au găsit o aplicație largă în sistemele de asistență a șoferului. Lucrările de detectare a marcajelor, obstacolelor de pe drum, recunoașterea semnelor etc. s-au desfășurat activ în anii 90. Au atins însă un nivel suficient (atât în ceea ce privește acuratețea și fiabilitatea metodelor în sine, cât și în ceea ce privește performanța procesoarelor capabile să execute în timp real metodele corespunzătoare) au atins în principal în ultimul deceniu.

Un exemplu notabil este tehnicile de vedere stereo utilizate pentru a detecta obstacolele de pe drum. Aceste metode pot fi destul de critice în ceea ce privește fiabilitatea, acuratețea și performanța. În special, pentru a detecta pietonii, ar putea fi necesar să se construiască o hartă densă a zonei la o scară apropiată de timp real. Aceste metode pot necesita sute de operații per pixel și precizia obținută cu dimensiuni de imagine de cel puțin un megapixel, adică sute de milioane de operații pe cadru (câteva miliarde sau mai multe operațiuni pe secundă).
Este demn de remarcat faptul că progresul general în domeniul viziunii computerizate nu este în niciun caz asociat doar cu dezvoltarea hardware-ului. Acesta din urmă deschide doar oportunități pentru utilizarea metodelor de procesare a imaginilor costisitoare din punct de vedere computațional, dar și aceste metode în sine trebuie dezvoltate. În ultimii 10-15 ani, metodele de comparare a imaginilor scenelor tridimensionale, metodele de restaurare a hărților cu gamă densă bazate pe viziune stereo, metodele de detectare și recunoaștere a fețelor etc. au fost aduse în practică efectiv. Principii generale soluțiile problemelor corespunzătoare prin aceste metode nu s-au schimbat, dar s-au îmbogățit cu o serie de detalii tehnice netriviale și trucuri matematice care au făcut ca aceste metode să aibă succes.
Revenind la sistemele de asistență a șoferului, nu se poate să nu menționăm metode moderne de detectare a pietonilor, în special, bazate pe histograme de gradient orientate. Metodele moderne de învățare automată, care vor fi discutate mai târziu, au permis pentru prima dată computerului mai bun decât un bărbat rezolva o sarcină vizuală atât de generală precum recunoașterea semnelor rutiere, dar nu prin utilizarea mijloace speciale formarea imaginii, dar datorită algoritmilor de recunoaștere care au primit exact aceleași informații ca și intrare ca o persoană.
Una dintre realizările tehnice semnificative a fost mașina autonomă de la Google, care, totuși, folosește un set bogat de senzori pe lângă camera video și, de asemenea, nu funcționează pe drumuri necunoscute (nefilmate anterior) și în condiții meteorologice nefavorabile.
Astfel, sistemele de asistență pentru șofer necesită soluționarea diferitelor probleme de vedere computerizată, printre care:
- vedere stereo;
- detectarea obstacolelor de pe drumuri;
- recunoașterea indicatoarelor rutiere, a marcajelor, a pietonilor și a mașinilor;
- sarcini, care necesită și mențiune, legate de monitorizarea stării șoferului.
Aplicatii mobile
Chiar și mai masive în comparație cu robotica de uz casnic și sistemele de asistență pentru șofer sunt sarcinile de viziune computerizată pentru personal dispozitive mobile, precum smartphone-uri, tablete etc. În special, numărul de telefoane mobile este în continuă creștere și a depășit deja aproape populația Pământului. În același timp, majoritatea telefoanelor sunt acum produse cu camere. În 2009, numărul acestor telefoane a depășit un miliard, creând o piață colosală pentru sistemele de imagistică și viziunea computerizată, care este departe de a fi saturată, în ciuda numeroaselor proiecte de cercetare-dezvoltare realizate atât de producătorii de dispozitive mobile înșiși, cât și de un număr mare de start-up-uri. . .

O parte din sarcinile de procesare a imaginilor pentru dispozitivele mobile cu camere este aceeași ca și pentru camere digitale. Principala diferență constă în calitatea obiectivelor și în condițiile de fotografiere. Un exemplu este sarcina de a sintetiza imagini cu gamă dinamică înaltă (HDRI) din mai multe imagini realizate la expuneri diferite. În cazul dispozitivelor mobile, există mai mult zgomot în imagini, cadrele se formează cu un interval de timp mare, iar deplasarea camerei în spațiu este de asemenea mai mare, ceea ce complică sarcina de a obține imagini HDRI de înaltă calitate, ceea ce în acest caz. trebuie rezolvat pe procesorul unui telefon mobil. În acest sens, rezolvarea unor probleme aparent identice pt diferite dispozitive poate varia, ceea ce face ca aceste soluții să fie încă solicitate pe piață.
Cu toate acestea, un interes mai mare sunt aplicațiile noi care nu erau disponibile anterior pe piață. O clasă largă de astfel de aplicații pentru dispozitivele mobile personale este asociată cu sarcini de realitate augmentată, care pot fi foarte diverse. Acestea includ aplicații de jocuri (care necesită afișarea consecventă a obiectelor virtuale deasupra scenei reale pe măsură ce camera se mișcă), precum și diverse aplicații de divertisment în general, aplicații de călătorie (recunoașterea punctelor de interes cu informații despre acestea), precum și multe alte aplicații legate de regăsirea informațiilor și recunoașterea obiectelor: recunoașterea inscripțiilor în limbi străine cu afișarea traducerii acestora, recunoașterea cărților de vizită cu introducerea automată a informațiilor în agenda telefonică, precum și recunoașterea feței cu extragerea de informații din carte de telefoane, recunoașterea posterului de film (înlocuirea imaginii afișului cu un trailer de film), etc.
Sistemele de realitate augmentată pot fi create sub forma unor dispozitive specializate precum Google Glass, ceea ce mărește și mai mult potențialul inovator al metodelor de viziune computerizată.

Astfel, clasa problemelor de vedere computerizată ale căror soluții pot fi aplicate în aplicațiile mobile este extrem de largă. Metodele de potrivire (identificarea punctelor conjugate) a imaginilor au o gamă largă de aplicații, inclusiv evaluarea structurii tridimensionale a scenei și determinarea modificărilor de orientare a camerei și a metodelor de recunoaștere a obiectelor, precum și analiza fețelor oamenilor. Cu toate acestea, un număr nelimitat de aplicatii mobile, ceea ce va necesita dezvoltarea unor metode specializate de viziune computerizată. Iată doar două astfel de exemple: telefon mobil cu decodarea automată a unui joc într-un joc de societate și reconstrucția traiectoriei unei crose de golf la lovire.
Găsirea și învățarea informațiilor
Multe sarcini de realitate augmentată sunt strâns legate de regăsirea informațiilor (deci unele sisteme, cum ar fi Google Goggles, este dificil de atribuit unei anumite zone), care prezintă un interes independent semnificativ.

Sarcinile de căutare a imaginilor după conținut sunt, de asemenea, diverse. Acestea includ potrivirea imaginilor la căutarea de imagini cu obiecte unice, cum ar fi structuri arhitecturale, sculpturi, picturi etc., detectarea și recunoașterea în imagini a obiectelor din clase de diferite grade de generalitate (mașini, animale, mobilier, fețe ale oamenilor etc.). , precum și subclasele acestora), categorizarea scenei (oraș, pădure, munți, coastă etc.). Aceste sarcini pot fi întâlnite în diverse aplicații - pentru sortarea imaginilor în albume foto digitale de acasă, pentru căutarea produselor după imaginile lor în magazinele online, pentru extragerea de imagini în sistemele de informații geografice, pentru sisteme identificare biometrică, pentru căutare de imagini specializate în în rețelele sociale(de exemplu, căutarea fețelor oamenilor care sunt atractive pentru utilizator), etc., până la căutarea de imagini pe Internet.
Atât progresele deja înregistrate, cât și perspectivele pentru continuarea acestuia sunt văzute în exemplul Provocării de recunoaștere vizuală la scară largă, în care numărul claselor recunoscute a crescut de la 20 în 2010 la 200 în 2013.

Recunoașterea obiectelor din atâtea clase este acum de neconceput fără implicarea metodelor de învățare automată în domeniul viziunii computerizate. Una dintre zonele extrem de populare aici este rețelele de învățare profundă concepute pentru a construi automat sisteme de caracteristici pe mai multe niveluri pentru o recunoaștere ulterioară. Cererea pentru această direcție este vizibilă din faptele achiziției diferitelor startup-uri de către corporații precum Google și Facebook. Deci, în 2013, Google a cumpărat DNNresearch, iar la începutul lui 2014, startup-ul DeepMind. Mai mult, Facebook a concurat și pentru achiziționarea ultimului startup (care angajase anterior un astfel de specialist precum Jan Le Kuhn pentru a conduce dezvoltarea de lider în laborator în domeniul învățării profunde), iar costul de achiziție a fost de 400 de milioane de dolari. Merită menționând că metoda menționată, care a câștigat la concursul de recunoaștere a semnelor rutiere, se bazează și pe rețele de deep learning.
Metodele de învățare profundă necesită resurse de calcul uriașe și chiar și învățarea recunoașterii unei clase limitate de obiecte poate dura câteva zile de lucru pe un cluster de calcul. În același timp, metode și mai puternice, dar care necesită și mai multe resurse de calcul, pot fi dezvoltate în viitor.
Concluzie
Am luat în considerare doar cele mai comune aplicații de viziune computerizată pentru utilizatorul în masă. Cu toate acestea, există multe alte aplicații, mai puțin tipice. De exemplu, metodele de viziune computerizată pot fi utilizate în microscopie, tomografie cu coerență optică, holografie digitală. Există numeroase aplicații ale metodelor de prelucrare și analiză a imaginilor în diverse domenii profesionale - biomedicină, industria spațială, criminalistică etc.

Reconstrucția unui profil 3D al unei foi de metal observată cu un microscop folosind metoda „depth out of focus”
În prezent, numărul aplicațiilor relevante de viziune computerizată continuă să crească. În special, sarcinile legate de analiza datelor video devin disponibile pentru soluționare. Dezvoltarea activă a televiziunii tridimensionale extinde ordinea sistemelor de viziune computerizată, pentru crearea cărora nu au fost încă dezvoltați algoritmi eficienți și sunt necesari alții mai substanțiale. putere de calcul. O astfel de sarcină solicitată este, în special, sarcina de a converti videoclipuri 2D în 3D.
Nu este surprinzător că instrumentele speciale de calcul continuă să fie utilizate în mod activ în fruntea sistemelor de viziune computerizată. În special, acum popular GPU-uri scop general(GPGPU) și cloud computing. Cu toate acestea, soluțiile corespunzătoare curg treptat în segment calculatoare personale cu o extindere semnificativă a posibilelor aplicaţii.
Domeniul de aplicare al vederii computerizate este foarte larg: de la cititoare de coduri de bare din supermarketuri la realitate augmentată. În această prelegere, veți afla unde este utilizată viziunea computerizată și cum funcționează, cum arată imaginile digitale, ce sarcini din acest domeniu sunt relativ ușor de rezolvat, care sunt dificile și de ce.
Prelecția este concepută pentru elevii de liceu - studenți ai Small ShAD, dar și adulții pot învăța o mulțime de lucruri utile din ea.
Abilitatea de a vedea și recunoaște obiecte este o posibilitate naturală și obișnuită pentru o persoană. Cu toate acestea, pentru computer până acum - aceasta este o sarcină extrem de dificilă. Acum se încearcă să se învețe computerul cel puțin o fracțiune din ceea ce o persoană folosește în fiecare zi, fără măcar să observe acest lucru.
Probabil, cel mai adesea o persoană obișnuită întâlnește viziunea computerizată la casă dintr-un supermarket. Cu siguranță, vorbim despre citirea codurilor de bare. Au fost special concepute astfel încât să facă procesul de citire cât mai ușor pentru computer. Există însă și sarcini mai complexe: citirea numerelor de mașini, analiza imaginilor medicale, detectarea defectelor în producție, recunoașterea feței etc. Utilizarea viziunii computerizate pentru a crea sisteme de realitate augmentată se dezvoltă activ.
Diferența dintre viziunea umană și computerizată
Copilul învață să recunoască obiectele treptat. El începe să-și dea seama cum se schimbă forma unui obiect în funcție de poziția și iluminarea acestuia. În viitor, atunci când recunoaște obiecte, o persoană se concentrează pe experiența anterioară. În timpul vieții sale, o persoană acumulează o cantitate imensă de informații, procesul de învățare a unei rețele neuronale nu se oprește nicio secundă. Nu este deosebit de dificil pentru o persoană să restabilească perspectiva dintr-o imagine plată și să-și imagineze cum ar arăta totul în trei dimensiuni.Toate acestea sunt mult mai dificile pentru un computer. Și în primul rând din cauza problemei acumulării de experiență. Este necesar să se colecteze un număr mare de exemple, care până acum nu are prea mult succes.
În plus, atunci când recunoaște un obiect, o persoană ține întotdeauna cont de mediul înconjurător. Dacă scoateți un obiect din mediul său familiar, va deveni mult mai dificil să îl recunoașteți. Și aici joacă un rol experiența acumulată de-a lungul unei vieți, pe care computerul nu o are.
Baiat sau fata?
Imaginați-vă că trebuie să învățăm cum să determinăm sexul unei persoane (îmbrăcată!) dintr-o fotografie dintr-o privire. Mai întâi trebuie să determinați factorii care pot indica apartenența la un anumit obiect. În plus, trebuie să colectați setul de antrenament. Este de dorit ca acesta să fie reprezentativ. În cazul nostru, vom lua ca eșantion de antrenament pe toți cei prezenți în audiență. Și să încercăm să găsim factorii distinctivi pe baza lor: de exemplu, lungimea părului, prezența unei barbi, machiaj și îmbrăcăminte (fustă sau pantaloni). Știind ce procent de reprezentanți de același sex au întâlnit anumiți factori, putem crea reguli destul de clare: prezența acestor sau a altor combinații de factori cu o anumită probabilitate ne va permite să spunem ce gen este persoana din fotografie.Învățare automată
Desigur, este foarte simplu și exemplu condițional cu câțiva factori de nivel superior. Există mult mai mulți factori în sarcinile reale care sunt setate pentru sistemele de viziune computerizată. Determinarea lor manuală și calcularea dependențelor este o sarcină imposibilă pentru o persoană. Prin urmare, în astfel de cazuri, învățarea automată este indispensabilă. De exemplu, puteți defini câteva zeci de factori inițiali, precum și să stabiliți exemple pozitive și negative. Și deja dependențele dintre acești factori sunt selectate automat, este întocmită o formulă care vă permite să luați decizii. Destul de des, factorii înșiși sunt alocați automat.Imagine în cifre
Cel mai des folosit spațiu de culoare pentru imaginile digitale este RGB. În ea, fiecăreia dintre cele trei axe (canale) i se atribuie propria culoare: roșu, verde și albastru. Fiecărui canal îi sunt alocați 8 biți de informații, respectiv, intensitatea culorii pe fiecare axă poate lua valori în intervalul de la 0 la 255. Toate culorile din spațiul digital RGB sunt obținute prin amestecarea a trei culori primare.Din păcate, RGB nu este întotdeauna potrivit pentru analiza informațiilor. Experimentele arată că proximitatea geometrică a culorilor este destul de departe de modul în care o persoană percepe apropierea anumitor culori unele de altele.
Dar există și alte spații de culoare. Spațiul HSV (Hue, Saturation, Value) este foarte interesant în contextul nostru. Are o axă Value care indică cantitatea de lumină. I se alocă un canal separat, spre deosebire de RGB, unde această valoare trebuie calculată de fiecare dată. De fapt, aceasta este o versiune alb-negru a imaginii cu care puteți lucra deja. Nuanța este reprezentată ca un unghi și este responsabilă pentru tonul principal. Saturația culorii depinde de valoarea Saturation (distanța de la centru la margine).

HSV este mult mai aproape de modul în care gândim culorile. Dacă arăți un obiect roșu și verde unei persoane în întuneric, aceasta nu va putea distinge culorile. Același lucru se întâmplă și în cazul HSV. Cu cât mergem mai în jos pe axa V, cu atât diferența dintre nuanțe devine mai mică, pe măsură ce intervalul valorilor de saturație scade. În diagramă, arată ca un con, deasupra căruia este un punct extrem de negru.
Culoare și lumină
De ce este important să avem date despre cantitatea de lumină? În majoritatea cazurilor, în viziunea computerizată, culoarea nu contează, deoarece nu poartă niciuna Informații importante. Să ne uităm la două imagini: color și alb-negru. Recunoașterea tuturor obiectelor pe varianta alb-negru nu este mult mai dificilă decât pe cea color. În acest caz, culoarea nu are nicio sarcină suplimentară pentru noi și sunt create multe probleme de calcul. Când lucrăm cu o versiune color a unei imagini, cantitatea de date este aproximativ cuburi.
Culoarea este folosită numai în cazuri rare când, dimpotrivă, permite simplificarea calculelor. De exemplu, atunci când trebuie să detectați o față: este mai ușor să găsiți mai întâi locația posibilă a acesteia în imagine, concentrându-vă pe gama de tonuri ale pielii. Acest lucru elimină nevoia de a analiza întreaga imagine.
Caracteristici locale și globale
Caracteristicile prin care analizăm imaginea sunt locale și globale. Privind această imagine, cei mai mulți vor spune că înfățișează o mașină roșie:
Un astfel de răspuns implică faptul că o persoană a identificat un obiect în imagine, ceea ce înseamnă că a descris o caracteristică locală a culorii. În mare, imaginea arată o pădure, un drum și o mașină mică. Din punct de vedere al suprafeței, mașina ocupă o parte mai mică. Dar înțelegem că mașina din această imagine este cel mai important obiect. Dacă unei persoane i se oferă să găsească imagini similare cu aceasta, va selecta în primul rând imagini în care există o mașină roșie.
Detectare și segmentare
În viziunea computerizată, acest proces se numește detectare și segmentare. Segmentarea este împărțirea unei imagini în mai multe părți care sunt legate între ele vizual sau semantic. Iar detectarea este detectarea obiectelor din imagine. Detectarea trebuie să fie clar diferențiată de recunoaștere. Să presupunem că un semn rutier poate fi detectat în aceeași imagine cu o mașină. Dar este imposibil să-l recunoaștem, din moment ce este întors spre noi. reversul. De asemenea, atunci când recunoaște fețele, detectorul poate determina locația feței, iar „recunoașterea” va spune deja a cui este față.
Descriptori și cuvinte vizuale
Există multe abordări diferite ale recunoașterii.De exemplu, aceasta: în imagine, mai întâi trebuie să selectați puncte interesante sau locuri interesante. Ceva diferit de fundal: puncte luminoase, tranziții etc. Există mai mulți algoritmi pentru a face acest lucru.
Una dintre cele mai comune modalități este numită Diferența Gaussienilor (DoG). Încețoșând imaginea cu diferite raze și comparând rezultatele, puteți găsi cele mai contrastante fragmente. Zonele din jurul acestor fragmente sunt cele mai interesante.
Imaginea de mai jos arată cum arată. Datele primite sunt scrise în descriptori.

Pentru ca aceiași descriptori să fie recunoscuți ca atare, indiferent de rotațiile din plan, aceștia sunt rotiți astfel încât cei mai mari vectori să fie rotți în aceeași direcție. Acest lucru nu se face întotdeauna. Dar dacă trebuie să detectați două obiecte identice situate în planuri diferite.
Descriptorii pot fi scriși în formă numerică. Un mâner poate fi reprezentat ca un punct într-o matrice multidimensională. Avem o matrice bidimensională în ilustrație. Descriptorii noștri au intrat în asta. Și le putem grupa - le împărțim în grupuri.

În continuare, descriem o zonă în spațiu pentru fiecare cluster. Când un descriptor se încadrează în această zonă, devine important pentru noi nu ceea ce a fost, ci în care dintre zone s-a înscris. Și apoi putem compara imagini, determinând câți descriptori ai unei imagini au ajuns în aceleași grupuri ca și descriptorii unei alte imagini. Astfel de grupuri pot fi numite cuvinte vizuale.
Pentru a găsi nu doar imagini identice, ci și imagini ale obiectelor similare, trebuie să faceți o mulțime de imagini ale acestui obiect și multe imagini în care nu este. Apoi selectați descriptori dintre ei și grupați-i. În continuare, trebuie să aflați în ce grupuri au căzut descriptorii din imaginile care conțineau obiectul de care aveam nevoie. Acum știm că dacă descriptorii din noua imagine se încadrează în aceleași grupuri, înseamnă că obiectul dorit este prezent pe ea.
Coincidența descriptorilor nu este încă o garanție a identității obiectelor care îi conțin. O modalitate de verificare suplimentară este validarea geometrică. În acest caz, se compară locația descriptorilor unul față de celălalt.
Recunoaștere și clasificare
Pentru simplitate, să ne imaginăm că putem împărți toate imaginile în trei clase: arhitectură, natură și portret. La rândul nostru, putem împărți natura în plante, animale și păsări. Și după ce am înțeles deja că aceasta este o pasăre, putem spune care: o bufniță, un pescăruș sau o cioară.
Diferența dintre recunoaștere și clasificare este destul de relativă. Dacă am găsit o bufniță în imagine, atunci aceasta este mai mult o recunoaștere. Dacă este doar o pasăre, atunci acesta este un fel de opțiune intermediară. Și dacă natura este cu siguranță o clasificare. Acestea. diferența dintre recunoaștere și clasificare este cât de adânc am trecut prin copac. Și cu cât viziunea computerizată avansează, cu atât limita dintre clasificare și recunoaștere va aluneca mai jos.
Să ne întoarcem la copilărie și să ne amintim de fantezie. Ei bine, cel puțin Star Wars, unde există un robot umanoid atât de galben. Merge cumva magic și se orientează în spațiu. De fapt, acest robot are „ochi” și „vede” spațiul înconjurător. Dar cum pot computerele să vadă ceva? Când privim ceva, înțelegem ceea ce vedem; pentru noi, informațiile vizuale sunt semnificative. Dar prin conectarea camerelor video la computer, vom obține doar un set de zerouri și unele pe care le va citi de la această cameră video. Cum poate un computer să „înțeleagă” ceea ce „vede”? Pentru a răspunde la această întrebare, a fost creată o disciplină științifică precum Computer Vision (Computer vision). În esență, Computer Vision este știința modului de a crea algoritmi care analizează și caută imagini Informatii utile(informații de care are nevoie robotul pentru a naviga în funcție de datele venite de la camera video). Sarcina vederii computerizate este, de fapt, o sarcină.
Există mai multe direcții și abordări în Computer Vision:
- Preprocesarea imaginii.
- Segmentarea.
- Selectarea contururilor.
- Găsirea punctelor speciale.
- Găsirea obiectelor într-o imagine.
- Recunoasterea formelor.
Să le analizăm mai detaliat.
Preprocesarea imaginii. De regulă, înainte de a analiza imaginea, este necesar să se efectueze o preprocesare, care va facilita analiza. De exemplu, eliminați zgomotul sau unele mici detalii minore care interferează cu analiza sau efectuați o altă prelucrare care va facilita analiza. În special, un filtru de estompare a imaginii este utilizat pentru a suprima zgomotul și detaliile fine.
Exemplu, imagine zgomotoasă:
După aplicarea Gaussian Blur

Cu toate acestea, are un dezavantaj semnificativ: împreună cu suprimarea zgomotului, granițele dintre zonele imaginii sunt neclare, iar detaliile mici nu dispar, se transformă pur și simplu în pete. Pentru a elimina aceste deficiențe, se utilizează filtrarea mediană. Face față bine zgomotului impulsiv și îndepărtarii fine a detaliilor, iar marginile nu sunt neclare. Cu toate acestea, filtrarea mediană nu va face față zgomotului gaussian.
Segmentarea. Segmentarea este împărțirea unei imagini în regiuni. De exemplu, o zonă este fundalul, cealaltă este un obiect specific. Sau, de exemplu, avem o fotografie cu unde se află plaja mării. Îl împărțim în zone: mare, plajă, cer. Pentru ce este segmentarea? Ei bine, de exemplu, avem o sarcină de a găsi un obiect în imagine. Pentru a accelera, limităm zona de căutare la un anumit segment, dacă știm sigur că obiectul poate fi doar în această zonă. Sau, de exemplu, în geoinformatică, poate exista o sarcină de segmentare a fotografiilor prin satelit sau aeriene.
Exemplu. Iată imaginea noastră originală:

Și iată segmentarea sa:

În acest caz, trăsăturile texturale au fost utilizate pentru segmentare.
Selectarea contururilor. De ce există un contur într-o imagine? Să presupunem că trebuie să rezolvăm problema de a găsi chipul unei persoane într-o fotografie. Să presupunem că am încercat mai întâi să rezolvăm această problemă „pe frunte” - enumerare contonantă. Luăm un „pătrat” cu imaginea feței și îl comparăm pixel cu pixel cu imaginea, mișcând pixelul pătrat cu pixel de la stânga la dreapta și așa mai departe pentru fiecare linie de pixeli. Este clar că acest lucru va funcționa prea mult timp, în plus, un astfel de algoritm nu va găsi nicio față, ci doar una anume. Și apoi, dacă îl rotiți puțin sau schimbați scara, atunci asta este tot, căutarea nu va mai funcționa. Un alt lucru este dacă avem un contur de imagine și un contur de față. Putem descrie liniile de contur în alt mod decât bitmap, de exemplu, ca o listă de coordonate ale punctelor sale, ca un grup de linii descrise prin diferite formule matematice. Pe scurt, selectăm un contur, îl putem vectoriza și nu mai căutam un raster între un raster, ci un obiect vectorial între obiectele vectoriale. Acest lucru este mult mai rapid și, în plus, atunci descrierea obiectelor poate fi invariantă la rotație și/sau la scară (adică putem găsi obiecte chiar dacă sunt rotite sau scalate).
Acum apare întrebarea: cum să selectați un contur? De regulă, se obține mai întâi așa-numita pregătire a conturului, cel mai adesea este un gradient (rata de modificare a luminozității). Adică, după ce am primit un gradient de imagine, vom vedea zone albe în care avem modificări bruște ale luminozității și zone negre în care luminozitatea se schimbă fără probleme sau nu se schimbă deloc. Cu alte cuvinte, toate marginile noastre vor fi evidențiate cu dungi albe. În continuare, îngustăm aceste dungi albe și obținem un contur (dacă descriem pe scurt ce face algoritmul pentru obținerea unui contur). În prezent, există o serie de algoritmi standard de extracție a conturului, de exemplu algoritmul Canny, care este implementat în biblioteca OpenCV.
Un exemplu de selecție a conturului.
Imagine originală:

Contururi selectate:
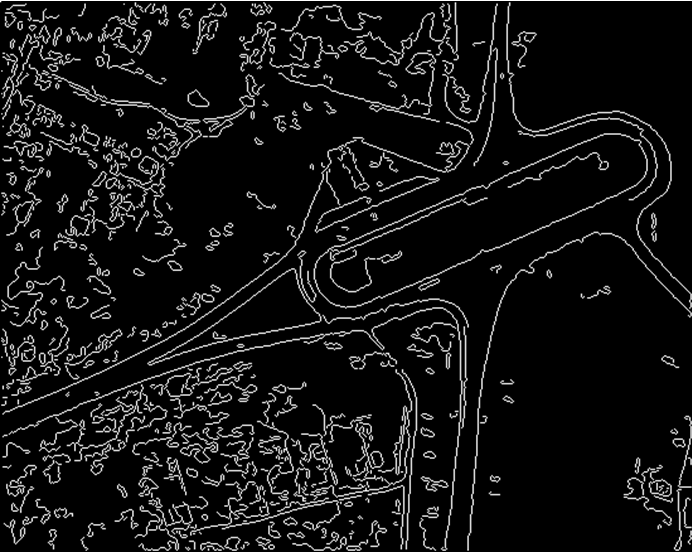
Găsirea punctelor speciale. O altă metodă de analiză a unei imagini este găsirea punctelor singulare pe ea. Punctele speciale pot fi, de exemplu, colțuri, luminozitate extremă, precum și alte caracteristici ale imaginii. Cu puncte speciale, puteți face aproximativ la fel ca și cu contururile - descrieți în formă vectorială. De exemplu, puteți descrie poziția relativă a punctelor în termeni de distanțe dintre puncte. Când obiectele sunt rotite, distanța nu se modifică, ceea ce înseamnă că o astfel de descriere va fi invariabilă față de rotație. Și pentru ca modelul să fie și invariabil la scară, puteți descrie nu distanța, ci relația dintre distanțe - într-adevăr, dacă distanța unei perechi de puncte este de două ori mai mare decât a celeilalte perechi de puncte, va fi întotdeauna de două ori. la fel de mare, indiferent dacă de câte ori am mărit sau redus obiectul. În prezent, există mulți algoritmi tipici pentru găsirea punctelor singulare, de exemplu, detectorul Harris, Moravec, MSER, AKAZE și așa mai departe. Mulți dintre algoritmii existenți de găsire a punctelor singulare sunt implementați în OpenCV.
Recunoasterea formelor. Acest proces are loc atunci când imaginea este analizată, contururile sunt selectate pe ea și convertite în formă vectorială sau sunt găsite puncte singulare și poziția lor relativă este calculată (sau ambele împreună). În general, s-a obținut un set de caracteristici, conform cărora se realizează definiția a ce obiecte sunt în imagine. Pentru a face acest lucru, sunt executați diverși algoritmi euristici, de exemplu, . În general, cum să recunoaștem imaginile se numește o întreagă știință Teoria recunoașterii modelelor.
Recunoașterea modelelor este atribuirea datelor inițiale unei anumite clase prin evidențierea trăsăturilor esențiale care caracterizează aceste date din masa totală de date neesențiale. Atunci când pun probleme de recunoaștere, ei încearcă să folosească un limbaj matematic, încercând – spre deosebire de teoria rețelelor neuronale artificiale, unde baza este obținerea unui rezultat prin experiment – să înlocuiască experimentul cu raționament logic și dovezi matematice. Enunțul clasic al problemei recunoașterii modelelor: dat un set de obiecte. Ele trebuie clasificate. O mulțime este reprezentată de submulțimi, care se numesc clase. Date: informații despre clase, o descriere a întregului set și o descriere a informațiilor despre un obiect a cărui apartenență la o anumită clasă este necunoscută. Este necesar, conform informațiilor disponibile despre clase și descrierea obiectului, să se stabilească cărei clase îi aparține acest obiect.
Există mai multe abordări ale recunoașterii modelelor:
- Enumerare. Fiecare clasă este specificată prin specificarea directă a membrilor săi. Această abordare este utilizată dacă sunt disponibile informații complete a priori despre toate obiectele posibile de recunoaștere. Imaginile prezentate sistemului sunt comparate cu descrierile date ale reprezentanților clasei și se referă la clasa căreia îi aparțin eșantioanele cele mai asemănătoare acestora. Această abordare se numește metoda de benchmarking. Este, de exemplu, aplicabil la recunoașterea caracterelor de mașină de scris dintr-un anumit font. Dezavantajul său este rezistența slabă la zgomot și distorsiuni în imaginile recunoscute.
- Setarea proprietăților generale. O clasă este definită prin specificarea unor caracteristici comune tuturor membrilor săi. Obiectul recunoscut în acest caz nu este comparat direct cu un grup de obiecte de referință. În descrierea sa primară, sunt evidențiate valorile unui anumit set de caracteristici, care sunt apoi comparate cu caracteristicile clasei date. Această abordare se numește potrivire de caracteristici. Este mai economică decât metoda de evaluare comparativă în ceea ce privește cantitatea de memorie necesară pentru stocarea descrierilor claselor. În plus, permite o anumită variabilitate a imaginilor recunoscute. Cu toate acestea, principala dificultate este de a determina setul complet de caracteristici care disting cu precizie membrii unei clase de membrii tuturor celorlalte.
- Clustering.În cazul în care obiectele sunt descrise prin vectori de caracteristici sau măsurători, clasa poate fi considerată ca un cluster. Recunoașterea se realizează pe baza calculării distanței (cel mai adesea aceasta este distanța euclidiană) a descrierii obiectului la fiecare dintre clusterele disponibile. Dacă clusterele sunt suficient de distanțate în spațiu, metoda de recunoaștere funcționează bine pentru estimarea distanțelor de la obiectul luat în considerare la fiecare dintre clustere. Complexitatea recunoașterii crește dacă clusterele se suprapun. Aceasta este de obicei o consecință a informațiilor inițiale insuficiente și poate fi rezolvată prin creșterea numărului de măsurători ale obiectului. Pentru a specifica clusterele inițiale, este recomandabil să folosiți procedura de învățare.
Pentru a efectua procedura de recunoaștere a modelelor, obiectele trebuie descrise cumva. Există, de asemenea, mai multe moduri de a descrie obiecte:
- Spațiul euclidian— obiectele sunt reprezentate prin puncte din spațiul euclidian al parametrilor lor calculați, reprezentați ca un set de măsurători;
- Liste de caracteristici- identificarea caracteristicilor calitative ale obiectului si construirea unui vector caracterizator;
- Descrierea structurala— identificarea elementelor structurale ale obiectului și determinarea relației lor.
Găsirea obiectelor într-o imagine. Sarcina de a găsi obiecte într-o imagine se rezumă la faptul că trebuie să găsim un obiect cunoscut anterior, de exemplu, fața unei persoane. Pentru aceasta obiect dat descriem prin niște semne și căutăm în imagine un obiect care satisface aceste semne. Această sarcină este similară cu sarcina de recunoaștere a modelelor, dar cu singura diferență că aici nu este necesar să se clasifice un obiect necunoscut, ci să se găsească unde se află în imagine un obiect cunoscut cu caracteristici date. Adesea, sarcina de a găsi obiecte în imagini este supusă cerințelor de performanță, deoarece aceasta trebuie făcută în timp real.
Un exemplu clasic de astfel de algoritmi este recunoașterea feței folosind metoda Viol Johnson. Deși această metodă a fost dezvoltată și introdusă în 2001 de Paul Viola și Michael Jones, este totuși fundamentală pentru căutarea în timp real a obiectelor de imagine. Principiile principale pe care se bazează metoda sunt:
- Imaginile sunt folosite în reprezentarea integrală, ceea ce vă permite să calculați rapid obiectele necesare;
- Se folosesc semne Haar, cu ajutorul cărora se caută obiectul dorit (în acest context, chipul și trăsăturile sale);
- Boosting este folosit (din engleză boost - îmbunătățire, întărire) pentru a selecta cele mai potrivite caracteristici pentru obiectul dorit dintr-o anumită parte a imaginii;
- Toate caracteristicile sunt introduse la intrarea clasificatorului, care dă rezultatul „adevărat” sau „fals”;
- Cascadele de caracteristici sunt folosite pentru a elimina rapid ferestrele în care nu se găsește nicio față.
Voi spune câteva cuvinte despre imaginea integrală. Cert este că în sarcinile de viziune computerizată este adesea necesară utilizarea metodei ferestrei de scanare: deplasăm fereastra pixel cu pixel pe întreaga imagine și executăm un anumit algoritm pentru fiecare pixel al ferestrei. După cum am spus la începutul articolului, această abordare este lentă, mai ales dacă dimensiunea ferestrei glisante și imaginea este mare. De exemplu, dacă avem o dimensiune a imaginii de 1000 pe 1000, atunci aceasta va fi de un milion de pixeli. Și dacă fereastra glisantă este de 10 pe 10, are 100 de pixeli și algoritmul care procesează o sută de pixeli trebuie executat de un milion de ori. La obținerea unei imagini integrale, parcurgem imaginea de 1 dată și obținem o matrice în care fiecare pixel este suma luminozității dreptunghiului delimitat de acest pixel și originea. Datorită unei astfel de matrice, putem calcula în doar 4 operații se poate calcula suma luminozității oricărui dreptunghi (cel puțin 10 cu 10, cel puțin 30 cu 30, cel puțin 100 cu 50). De regulă, în multe cazuri, procesarea în fereastra glisantă se reduce doar la calcularea sumei luminozităților.
Viziunea computerizată și recunoașterea imaginilor sunt o parte integrantă a (AI), care a câștigat o popularitate imensă de-a lungul anilor. În luna ianuarie a acestui an, a avut loc CES 2017, unde ați putut privi cele mai recente realizări în acest domeniu. Iată câteva exemple interesante utilizarea viziunii computerizate, care a putut fi văzută la expoziție.
8 Cazuri de utilizare Computer Vision
Veronica Elkina1. Mașini care se conduc singure
Cele mai mari standuri cu viziune computerizată aparțin industriei auto. La urma urmei, tehnologiile auto-conducere și semi-autonome funcționează, în mare parte, datorită vederii computerizate.
Produsele de la NVIDIA, care a făcut deja progrese mari în domeniul învățării profunde, sunt folosite în multe mașini cu conducere autonomă. De exemplu, supercomputerul NVIDIA Drive PX 2 servește deja drept platformă de bază pentru drone, Volvo, Audi, BMW și Mercedes-Benz.
Tehnologia de percepție artificială DriveNet de la NVIDIA este o viziune computerizată cu auto-învățare alimentată de rețele neuronale. Cu ajutorul lui, lidare, radare, camere și senzori ultrasonici capabil să recunoască mediu, marcaje rutiere, transport și multe altele.
3. Interfețe
Tehnologia de urmărire a ochilor care utilizează vederea computerizată este utilizată nu numai în laptopuri de gaming, dar și în calculatoarele obișnuite și corporative, astfel încât să poată fi controlate de oameni care nu își pot folosi mâinile. Tobii Dynavox PCEye Mini are dimensiunea unui pix și este accesoriul perfect discret pentru tablete și laptopuri. De asemenea, această tehnologie de urmărire a ochilor este folosită în jocuri noi și laptopuri conventionale Telefoane inteligente Asus și Huawei.
Între timp, controlul prin gesturi (tehnologia de vizualizare pe computer care poate recunoaște mișcările specifice ale mâinii) continuă să evolueze. Acum va fi folosit în viitoarele vehicule BMW și Volkswagen.

Noua interfață HoloActive Touch permite utilizatorilor să controleze ecranele 3D virtuale și să apese butoane în spațiu. Se poate spune că el este versiune simplă interfața holografică reală a lui Iron Man (chiar reacționează cu o ușoară vibrație la elementele care apasă în același mod). Datorită tehnologiilor precum ManoMotion, va fi ușor să adăugați control prin gesturi la aproape orice dispozitiv. Mai mult, pentru a obține controlul asupra unui obiect 3D virtual prin gesturi, ManoMotion folosește o cameră 2D obișnuită, astfel încât nu aveți nevoie de niciun echipament suplimentar.
Dispozitivul Singlecue Gen 2 de la eyeSight folosește viziunea computerizată (recunoașterea gesturilor, analiza feței, detectarea acțiunii) și vă permite să vă controlați televizorul, sistemul de iluminat inteligent și frigiderele cu gesturi.

hayo
Proiectul de crowdfunding al lui Hayo este, fără îndoială, cea mai interesantă interfață nouă de până acum. Această tehnologie vă permite să creați comenzi virtuale în toată casa - pur și simplu ridicând sau coborând mâna, puteți crește sau micșora volumul muzicii sau puteți aprinde lumina în bucătărie fluturând mâna peste blat. Totul funcționează datorită unui dispozitiv cilindric care folosește vederea computerizată, precum și unei camere integrate și senzori 3D, infraroșu și de mișcare.
4. Aparate de uz casnic
Camerele scumpe care arată ce se află în frigider nu mai par atât de revoluționare. Dar ce zici de o aplicație care analizează imaginea din camera încorporată a frigiderului și îți spune când rămâi fără anumite alimente?

Elegantul dispozitiv FridgeCam de la Smarter se montează pe peretele frigiderului și vă poate spune când este data de expirare, vă poate spune exact ce este în frigider și chiar vă poate recomanda rețete pentru alimente selectate. Dispozitivul este vândut la un preț neașteptat de accesibil - doar 100 USD.
5. Digital signage
Viziunea computerizată ar putea schimba modul în care arată bannerele și reclamele în magazine, muzee, stadioane și parcuri de distracție.
La standul Panasonic a fost prezentată o versiune demo a tehnologiei de proiectare a imaginilor pe steagurile. Cu ajutorul markerilor cu infraroșu invizibili pentru ochiul uman și al stabilizării video, această tehnologie poate proiecta reclame pe bannere suspendate și chiar pe steaguri fluturând în vânt. Mai mult, imaginea va arăta ca și cum ar fi într-adevăr imprimată pe ele.
6. Smartphone-uri și realitate augmentată
Mulți oameni au vorbit despre joc ca fiind prima aplicație de masă cu elemente (AR). Cu toate acestea, ca și alte aplicații care încearcă să urce într-un tren AR, acest joc a folosit mai mult GPS-ul și triangularea pentru a oferi utilizatorilor impresia că obiectul se află chiar în fața lor. Smartphone-urile de obicei nu folosesc deloc tehnologii reale de viziune computerizată.

Cu toate acestea, în noiembrie, Lenovo a lansat Phab2, primul smartphone care acceptă tehnologia Google Tango. Această tehnologie este o combinație de senzori și software de viziune pe computer care poate recunoaște imaginile, videoclipurile și lumea în timp real folosind obiectivul unei camere.

La CES, Asus a dezvăluit pentru prima dată ZenPhone AR, un smartphone compatibil Tango și Daydream de la Google. Smartphone-ul nu numai că poate urmări mișcările, analiza mediul și determina cu precizie poziția, dar folosește și procesorul Qualcomm Snapdragon 821, care vă permite să distribuiți încărcătura de date de viziune computerizată. Toate acestea ajută la aplicarea tehnologiilor reale de realitate augmentată, care analizează de fapt situația prin intermediul camerei smartphone-ului.
Mai târziu în acest an, Changhong H2, primul smartphone cu un scaner molecular încorporat, va fi lansat. Acesta colectează lumina care este reflectată de obiect și o sparge într-un spectru, apoi o analizează compoziție chimică. Mulțumită software folosind vederea computerizată, informațiile obținute pot fi folosite în diverse scopuri - de la prescrierea de medicamente și numărarea caloriilor până la determinarea stării pielii și calcularea nivelului de grăsime.
| Conferința Big Data va avea loc la Moscova pe 15 septembrie Conferința Big Data. Programul include cazuri de afaceri, soluții tehnice și realizări științifice ale celor mai buni specialiști în acest domeniu. Invităm pe toți cei interesați să lucreze cu date mari și care doresc să le aplice în afaceri reale. Urmărește conferința Big Data la |
Domeniul de aplicare al vederii computerizate este foarte larg: de la cititoare de coduri de bare din supermarketuri la realitate augmentată. În această prelegere, veți afla unde este utilizată viziunea computerizată și cum funcționează, cum arată imaginile digitale, ce sarcini din acest domeniu sunt relativ ușor de rezolvat, care sunt dificile și de ce.
Prelecția este concepută pentru elevii de liceu - studenți ai Small ShAD, dar și adulții pot învăța o mulțime de lucruri utile din ea.
Abilitatea de a vedea și recunoaște obiecte este o posibilitate naturală și obișnuită pentru o persoană. Cu toate acestea, pentru computer până acum - aceasta este o sarcină extrem de dificilă. Acum se încearcă să se învețe computerul cel puțin o fracțiune din ceea ce o persoană folosește în fiecare zi, fără măcar să observe acest lucru.
Probabil, cel mai adesea o persoană obișnuită întâlnește viziunea computerizată la casă dintr-un supermarket. Desigur, vorbim despre citirea codurilor de bare. Au fost special concepute astfel încât să facă procesul de citire cât mai ușor pentru computer. Există însă și sarcini mai complexe: citirea numerelor de mașini, analiza imaginilor medicale, detectarea defectelor în producție, recunoașterea feței etc. Utilizarea viziunii computerizate pentru a crea sisteme de realitate augmentată se dezvoltă activ.
Diferența dintre viziunea umană și computerizată
Copilul învață să recunoască obiectele treptat. El începe să-și dea seama cum se schimbă forma unui obiect în funcție de poziția și iluminarea acestuia. În viitor, atunci când recunoaște obiecte, o persoană se concentrează pe experiența anterioară. În timpul vieții sale, o persoană acumulează o cantitate imensă de informații, procesul de învățare a unei rețele neuronale nu se oprește nicio secundă. Nu este deosebit de dificil pentru o persoană să restabilească perspectiva dintr-o imagine plată și să-și imagineze cum ar arăta totul în trei dimensiuni.Toate acestea sunt mult mai dificile pentru un computer. Și în primul rând din cauza problemei acumulării de experiență. Este necesar să se colecteze un număr mare de exemple, care până acum nu are prea mult succes.
În plus, atunci când recunoaște un obiect, o persoană ține întotdeauna cont de mediul înconjurător. Dacă scoateți un obiect din mediul său familiar, va deveni mult mai dificil să îl recunoașteți. Și aici joacă un rol experiența acumulată de-a lungul unei vieți, pe care computerul nu o are.
Baiat sau fata?
Imaginați-vă că trebuie să învățăm cum să determinăm sexul unei persoane (îmbrăcată!) dintr-o fotografie dintr-o privire. Mai întâi trebuie să determinați factorii care pot indica apartenența la un anumit obiect. În plus, trebuie să colectați setul de antrenament. Este de dorit ca acesta să fie reprezentativ. În cazul nostru, vom lua ca eșantion de antrenament pe toți cei prezenți în audiență. Și să încercăm să găsim factorii distinctivi pe baza lor: de exemplu, lungimea părului, prezența unei barbi, machiaj și îmbrăcăminte (fustă sau pantaloni). Știind ce procent de reprezentanți de același sex au întâlnit anumiți factori, putem crea reguli destul de clare: prezența acestor sau a altor combinații de factori cu o anumită probabilitate ne va permite să spunem ce gen este persoana din fotografie.Învățare automată
Desigur, acesta este un exemplu foarte simplu și condiționat, cu un număr mic de factori de nivel înalt. Există mult mai mulți factori în sarcinile reale care sunt setate pentru sistemele de viziune computerizată. Determinarea lor manuală și calcularea dependențelor este o sarcină imposibilă pentru o persoană. Prin urmare, în astfel de cazuri, învățarea automată este indispensabilă. De exemplu, puteți defini câteva zeci de factori inițiali, precum și să stabiliți exemple pozitive și negative. Și deja dependențele dintre acești factori sunt selectate automat, este întocmită o formulă care vă permite să luați decizii. Destul de des, factorii înșiși sunt alocați automat.Imagine în cifre
Cel mai des folosit spațiu de culoare pentru imaginile digitale este RGB. În ea, fiecăreia dintre cele trei axe (canale) i se atribuie propria culoare: roșu, verde și albastru. Fiecărui canal îi sunt alocați 8 biți de informații, respectiv, intensitatea culorii pe fiecare axă poate lua valori în intervalul de la 0 la 255. Toate culorile din spațiul digital RGB sunt obținute prin amestecarea a trei culori primare.Din păcate, RGB nu este întotdeauna potrivit pentru analiza informațiilor. Experimentele arată că proximitatea geometrică a culorilor este destul de departe de modul în care o persoană percepe apropierea anumitor culori unele de altele.
Dar există și alte spații de culoare. Spațiul HSV (Hue, Saturation, Value) este foarte interesant în contextul nostru. Are o axă Value care indică cantitatea de lumină. I se alocă un canal separat, spre deosebire de RGB, unde această valoare trebuie calculată de fiecare dată. De fapt, aceasta este o versiune alb-negru a imaginii cu care puteți lucra deja. Nuanța este reprezentată ca un unghi și este responsabilă pentru tonul principal. Saturația culorii depinde de valoarea Saturation (distanța de la centru la margine).
HSV este mult mai aproape de modul în care gândim culorile. Dacă arăți un obiect roșu și verde unei persoane în întuneric, aceasta nu va putea distinge culorile. Același lucru se întâmplă și în cazul HSV. Cu cât mergem mai în jos pe axa V, cu atât diferența dintre nuanțe devine mai mică, pe măsură ce intervalul valorilor de saturație scade. În diagramă, arată ca un con, deasupra căruia este un punct extrem de negru.
Culoare și lumină
De ce este important să avem date despre cantitatea de lumină? În cele mai multe cazuri, în viziunea computerizată, culoarea nu contează, deoarece nu conține nicio informație importantă. Să ne uităm la două imagini: color și alb-negru. Recunoașterea tuturor obiectelor pe varianta alb-negru nu este mult mai dificilă decât pe cea color. În acest caz, culoarea nu are nicio sarcină suplimentară pentru noi și sunt create multe probleme de calcul. Când lucrăm cu o versiune color a unei imagini, cantitatea de date este aproximativ cuburi.
Culoarea este folosită numai în cazuri rare când, dimpotrivă, permite simplificarea calculelor. De exemplu, atunci când trebuie să detectați o față: este mai ușor să găsiți mai întâi locația posibilă a acesteia în imagine, concentrându-vă pe gama de tonuri ale pielii. Acest lucru elimină nevoia de a analiza întreaga imagine.
Caracteristici locale și globale
Caracteristicile prin care analizăm imaginea sunt locale și globale. Privind această imagine, cei mai mulți vor spune că înfățișează o mașină roșie:
Un astfel de răspuns implică faptul că o persoană a identificat un obiect în imagine, ceea ce înseamnă că a descris o caracteristică locală a culorii. În mare, imaginea arată o pădure, un drum și o mașină mică. Din punct de vedere al suprafeței, mașina ocupă o parte mai mică. Dar înțelegem că mașina din această imagine este cel mai important obiect. Dacă unei persoane i se oferă să găsească imagini similare cu aceasta, va selecta în primul rând imagini în care există o mașină roșie.
Detectare și segmentare
În viziunea computerizată, acest proces se numește detectare și segmentare. Segmentarea este împărțirea unei imagini în mai multe părți care sunt legate între ele vizual sau semantic. Iar detectarea este detectarea obiectelor din imagine. Detectarea trebuie să fie clar diferențiată de recunoaștere. Să presupunem că un semn rutier poate fi detectat în aceeași imagine cu o mașină. Dar este imposibil să-l recunoaștem, deoarece este întors la noi. De asemenea, atunci când recunoaște fețele, detectorul poate determina locația feței, iar „recunoașterea” va spune deja a cui este față.
Descriptori și cuvinte vizuale
Există multe abordări diferite ale recunoașterii.De exemplu, aceasta: în imagine, mai întâi trebuie să evidențiați punctele interesante sau punctele de interes. Ceva diferit de fundal: puncte luminoase, tranziții etc. Există mai mulți algoritmi pentru a face acest lucru.
Una dintre cele mai comune modalități este numită Diferența Gaussienilor (DoG). Încețoșând imaginea cu diferite raze și comparând rezultatele, puteți găsi cele mai contrastante fragmente. Zonele din jurul acestor fragmente sunt cele mai interesante.
Imaginea de mai jos arată cum arată. Datele primite sunt scrise în descriptori.
Pentru ca aceiași descriptori să fie recunoscuți ca atare, indiferent de rotațiile din plan, aceștia sunt rotiți astfel încât cei mai mari vectori să fie rotți în aceeași direcție. Acest lucru nu se face întotdeauna. Dar dacă trebuie să detectați două obiecte identice situate în planuri diferite.
Descriptorii pot fi scriși în formă numerică. Un mâner poate fi reprezentat ca un punct într-o matrice multidimensională. Avem o matrice bidimensională în ilustrație. Descriptorii noștri au intrat în asta. Și le putem grupa - le împărțim în grupuri.
În continuare, descriem o zonă în spațiu pentru fiecare cluster. Când un descriptor se încadrează în această zonă, devine important pentru noi nu ceea ce a fost, ci în care dintre zone s-a înscris. Și apoi putem compara imagini, determinând câți descriptori ai unei imagini au ajuns în aceleași grupuri ca și descriptorii unei alte imagini. Astfel de grupuri pot fi numite cuvinte vizuale.
Pentru a găsi nu doar imagini identice, ci și imagini ale obiectelor similare, trebuie să faceți o mulțime de imagini ale acestui obiect și multe imagini în care nu este. Apoi selectați descriptori dintre ei și grupați-i. În continuare, trebuie să aflați în ce grupuri au căzut descriptorii din imaginile care conțineau obiectul de care aveam nevoie. Acum știm că dacă descriptorii din noua imagine se încadrează în aceleași grupuri, înseamnă că obiectul dorit este prezent pe ea.
Coincidența descriptorilor nu este încă o garanție a identității obiectelor care îi conțin. O modalitate de verificare suplimentară este validarea geometrică. În acest caz, se compară locația descriptorilor unul față de celălalt.
Recunoaștere și clasificare
Pentru simplitate, să ne imaginăm că putem împărți toate imaginile în trei clase: arhitectură, natură și portret. La rândul nostru, putem împărți natura în plante, animale și păsări. Și după ce am înțeles deja că aceasta este o pasăre, putem spune care: o bufniță, un pescăruș sau o cioară.
Diferența dintre recunoaștere și clasificare este destul de relativă. Dacă am găsit o bufniță în imagine, atunci aceasta este mai mult o recunoaștere. Dacă este doar o pasăre, atunci acesta este un fel de opțiune intermediară. Și dacă natura este cu siguranță o clasificare. Acestea. diferența dintre recunoaștere și clasificare este cât de adânc am trecut prin copac. Și cu cât viziunea computerizată avansează, cu atât limita dintre clasificare și recunoaștere va aluneca mai jos.