Интерес к компьютерному зрению возник одним из первых в области искусственного интеллекта наряду с такими задачами, как автоматическое доказательство теорем и интеллектуальные игры. Даже архитектура первой искусственной нейронной сети - перцептрона - была предложена Фрэнком Розенблаттом, исходя из аналогии с сетчаткой глаза, а ее исследование проводилось на примере задачи распознавания изображений символов.
Значимость проблемы зрения никогда не вызывала сомнения, но одновременно ее сложность существенно недооценивалась. К примеру, легендарным по своей показательности стал случай, когда в 1966 г. один из основоположников области искусственного интеллекта, Марвин Минский, даже не сам собрался решить проблему искусственного зрения, а поручил это сделать одному студенту за ближайшее лето . При этом на создание программы, играющей на уровне гроссмейстера в шахматы, отводилось значительно большее время. Однако сейчас очевидно, что создать программу, обыгрывающую человека в шахматы, проще, чем создать адаптивную систему управления с подсистемой компьютерного зрения, которая бы смогла просто переставлять шахматные фигуры на произвольной реальной доске.
Прогресс в области компьютерного зрения определяется двумя факторами: развитие теории, методов, и развитие аппаратного обеспечения. Долгое время теория и академические исследования опережали возможности практического использования систем компьютерного зрения. Условно можно выделить ряд этапов развития теории.
- К 1970-м годам сформировался основной понятийный аппарат в области обработки изображений, являющийся основой для исследования проблем зрения. Также были выделены основные задачи, специфические для машинного зрения, связанные с оценкой физических параметров сцены (дальности, скоростей движения, отражательной способности поверхностей и т. д.) по изображениям, хотя ряд этих задач все еще рассматривался в весьма упрощенной постановке для «мира игрушечных кубиков».
- К 80-м сформировалась теория уровней представления изображений в методах их анализа. Своего рода отметкой окончания этого этапа служит книга Дэвида Марра «Зрение. Информационный подход к изучению представления и обработки зрительных образов».
- К 90-м оказывается сформированным систематическое представление о подходах к решению основных, уже ставших классическими, задач машинного зрения.
- С середины 90-х происходит переход к созданию и исследованию крупномасштабных систем компьютерного зрения, предназначенных для работы в различных естественных условиях.
- Текущий этап наиболее интересен развитием методов автоматического построения представлений изображений в системах распознавания изображений и компьютерного зрения на основе принципов машинного обучения.
В то же время прикладные применения ограничивались вычислительными ресурсами. Ведь чтобы выполнить даже простейшую обработку изображения, нужно хотя бы один раз просмотреть все его пиксели (и обычно не один раз). Для этого нужно выполнять как минимум сотни тысяч операций в секунду, что долгое время было невозможно и требовало упрощений.
К примеру, для автоматического распознавания деталей в промышленности могла использоваться черная лента конвейера, устраняющая необходимость отделения объекта от фона, или сканирование движущегося объекта линейкой фотодиодов со специальной подсветкой, что уже на уровне формирования сигнала обеспечивало выделение инвариантных признаков для распознавания без применения каких-либо сложных методов анализа информации. В оптико-электронных системах сопровождения и распознавания целей использовались физические трафареты, позволяющие «аппаратно» выполнять согласованную фильтрацию. Некоторые из этих решений являлись гениальными с инженерной точки зрения, но были применимы только в задачах с низкой априорной неопределенностью, и поэтому обладали, в частности, плохой переносимостью на новые задачи.
Не удивительно, что на 1970-е годы пришелся пик интереса и к оптическим вычислениям в обработке изображений. Они позволяли реализовать небольшой набор методов (преимущественно корреляционных) с ограниченными свойствами инвариантности, но весьма эффективным образом.
Постепенно, благодаря росту производительности процессоров (а также развитию цифровых видеокамер), ситуация изменилась. Преодоление определенного порога производительности, необходимого для осуществления полезной обработки изображений за разумное время, открыло путь для целой лавины приложений компьютерного зрения. Следует, однако, сразу подчеркнуть, что этот переход не был мгновенным и продолжается до сих пор.
В первую очередь, общеприменимые алгоритмы обработки изображений стали доступны для спецпроцессоров - цифровых сигнальных процессоров (ЦСП) и программируемых логических интегральных схем (ПЛИС), нередко совместно использовавшихся и находящих широкое применение до сих пор в бортовых и промышленных системах.

Однако действительно массовое применение методы компьютерного зрения получили лишь менее десяти лет назад, с достижением соответствующего уровня производительности процессоров у персональных и мобильных компьютеров. Таким образом, в плане практического применения системы компьютерного зрения прошли ряд этапов: этап индивидуального решения (как в части аппаратного обеспечения, так и алгоритмов) конкретных задач; этап применения в профессиональных областях (в особенности в промышленности и оборонной сфере) с использованием спецпроцессоров, специализированные системы формирования изображений и алгоритмы, предназначенные для работы в условиях низкой априорной неопределенности, однако эти решения допускали масштабирование; и этап массового применения.
Как видно, система машинного зрения включает следующие основные компоненты:

Наиболее массового применения достигают системы машинного зрения, использующие стандартные камеры и компьютеры в качестве первых двух компонент (именно к таким системам больше подходит термин «компьютерное зрение», хотя четкого разделения понятий машинного и компьютерного зрения нет). Однако, естественно, прочие системы машинного зрения обладают не меньшей значимостью. Именно выбор «нестандартных» способов формирования изображений (включая использование иных, помимо видимого, спектральных диапазонов, когерентного излучения, структурированной подсветки, гиперспектральных приборов, времяпролетных, всенаправленных и быстродействующих камер, телескопов и микроскопов и т. д.) существенно расширяет возможности систем машинного зрения. В то время как по возможностям алгоритмического обеспечения системы машинного зрения существенно уступают зрению человека, по возможностям получения информации о наблюдаемых объектах они существенно превосходят его. Однако вопросы формирования изображений составляют самостоятельную область, а методы работы с изображениями, полученными с использованием разных сенсоров, столь разнообразны, что их обзор выходит за рамки данной статьи. В этой связи мы ограничимся обзором систем компьютерного зрения, использующих обычные камеры.

Применение в робототехнике
Робототехника является традиционной областью применения машинного зрения. Однако основная доля парка роботов долгое время приходилась на промышленность, где очувствление роботов не было лишним, но благодаря хорошо контролируемым условиям (низкой недетерминированности среды) возможными оказывались узкоспециализированные решения, в том числе и для задач машинного зрения. Кроме того, промышленные приложения допускали использование дорогостоящего оборудования, включающего оптические и вычислительные системы.
В этой связи показательно (хотя и не связано только с системами компьютерного зрения) то, что доля парка роботов, приходящаяся на промышленных роботов, стала менее 50% лишь в начале 2000-х годов . Стала развиваться робототехника, предназначенная для массового потребителя. Для бытовых роботов, в отличие от промышленных, критичной является стоимость, а также время автономной работы, что подразумевает использование мобильных и встраиваемых процессорных систем. При этом такие роботы должны функционировать в недетерминированных средах. К примеру, в промышленности долгое время (да и по сей день) использовались фотограмметрические метки, наклеиваемые на объекты наблюдения или калибровочные доски, - для решения задач определения внутренних параметров и внешней ориентации камер. Естественно, необходимость наклеивать пользователю такие метки на предметы интерьера существенно ухудшила бы потребительские качества бытовых роботов. Не удивительно, что рынок бытовых роботов ждал для начала своего бурного развития достижения определенного уровня технологий, что произошло в конце 90-х.
Точкой отсчета этого события может служить выпуск первой версии робота AIBO (Sony), который, несмотря на сравнительно высокую цену ($2500), пользовался большим спросом. Первая партия этих роботов в количестве 5000 экземпляров была раскуплена в Интернете за 20 мин., вторая партия (также в 1999 г.) - за 17 с, и далее темп продаж составлял порядка 20 000 экземпляров в год.
Также в конце 90-х появились в массовом производстве устройства, которые можно было бы назвать бытовыми роботами в полном смысле этого слова. Наиболее типичными автономными бытовыми роботами являются роботы-пылесосы. Первой моделью, выпущенной в 2002 г. фирмой iRobot, стала Roomba. Затем появились роботы-пылесосы, выпущенные фирмами LG Electronics, Samsung и др. К 2008 г. суммарные объемы продаж роботов-пылесосов в мире составили более полумиллиона экземпляров в год.
Показательно то, что первые роботы-пылесосы, оснащенные системами компьютерного зрения, появились лишь в 2006 г. К этому моменту использование мобильных процессоров типа семейства ARM с частотой 200 МГц позволяло добиться сопоставления изображений трехмерных сцен внутри помещений на основе инвариантных дескрипторов ключевых точек в целях сенсорной локализации робота с частотой порядка 5 кадров/с. Использование зрения для определения роботом своего местоположения стало экономически оправданным, хотя еще недавно для этих целей производители предпочитали использовать сонары.
Дальнейшее повышение производительности мобильных процессоров позволяет ставить новые задачи для систем компьютерного зрения в бытовых роботах, число продаж которых по всему миру исчисляется уже миллионами экземпляров в год . Помимо задач навигации, от роботов, предназначенных для персонального использования, может потребоваться решение задач распознавания людей и их эмоций по лицам, распознавание жестов, предметов обстановки, включая столовые приборы и посуду, одежду, домашних животных и т. д., в зависимости от типа задачи, решаемой роботом. Многие из этих задач далеки от полного решения и являются перспективными с инновационной точки зрения.

Таким образом, современная робототехника требует решения широкого круга задач компьютерного зрения, включающего, в частности:
- набор задач, связанных с ориентацией во внешнем пространстве (например, задачу одновременной локализации и картографирования - Simultaneous Localization and Mapping, SLAM), определением расстояний до объектов и т. д;
- задачи по распознаванию различных объектов и интерпретации сцен в целом;
- задачи по обнаружению людей, распознаванию их лиц и анализу эмоций.
Системы помощи водителю
Помимо бытовых роботов, методы компьютерного зрения нашли широкое применение в системах помощи водителю. Работы по детектированию разметки, препятствий на дороге, распознаванию знаков и т. д. активно велись и в 90-х годах. Однако достаточного уровня (как по точности и надежности самих методов, так и по производительности процессоров, способных в масштабе реального времени выполнять соответствующие методы) они достигли преимущественно в последнем десятилетии.

Одним из показательных примеров являются методы стереозрения, используемые для обнаружения препятствий на дороге. Эти методы могут быть весьма критичны к надежности, точности и производительности. В частности, в целях обнаружения пешеходов может требоваться построение плотной карты дальности в масштабе, близком к реальному времени. Эти методы могут требовать сотен операций на пиксель и точности, достигаемой при размерах изображений не менее мегапиксела, то есть при сотнях миллионов операций на кадр (нескольких миллиардов и более операций в секунду).
Стоит отметить, что общий прогресс в области компьютерного зрения отнюдь не связан только с развитием аппаратного обеспечения. Последнее лишь открывает возможности для применения вычислительно затратных методов обработки изображений, но сами эти методы также нуждаются в разработке. За последние 10–15 лет были доведены до эффективного практического использования методы сопоставления изображений трехмерных сцен , методы восстановления плотных карт дальности на основе стереозрения , методы обнаружения и распознавания лиц и т. д. Общие принципы решения соответствующих задач данными методами не изменились, но они обогатились рядом нетривиальных технических деталей и математических приемов, сделавших эти методы успешными.
Возвращаясь к системам помощи водителю, нельзя не упомянуть про современные методы детектирования пешеходов, в частности, на основе гистограмм ориентированных градиентов . Современные методы машинного обучения, о которых еще будет сказано позднее, впервые позволили компьютеру лучше человека решать такую достаточно общую зрительную задачу, как распознавание дорожных знаков , но не благодаря использованию специальных средств формирования изображений, а благодаря алгоритмам распознавания, получавшим на вход в точности ту же информацию, что и человек.
Одним из существенных технических достижений стал беспилотный автомобиль Google, который, однако, использует богатый набор сенсоров помимо видеокамеры, а также не работает на незнакомых (заранее не отснятых) дорогах и при плохих погодных условиях.
Таким образом, для систем помощи водителю требуется решение разных задач компьютерного зрения, включая:
- стереозрение;
- обнаружение препятствий на дорогах;
- распознавание дорожных знаков, разметки, пешеходов и автомобилей;
- задачи, также требующие упоминания, связанные с контролем состояния водителя.
Мобильные приложения
Еще более массовыми по сравнению с бытовой робототехникой и системами помощи водителю являются задачи компьютерного зрения для персональных мобильных устройств, таких как смартфоны, планшеты и т. д. В частности, число мобильных телефонов неуклонно растет и уже практически превысило по численности население Земли. При этом основная доля телефонов выпускается сейчас с камерами. В 2009 г. количество таких телефонов превысило миллиард, что создает колоссальный по размерам рынок для систем обработки изображений и компьютерного зрения, который далек от насыщения, несмотря на многочисленные R&D-проекты, проводящиеся как самими фирмами - изготовителями мобильных устройств, так и большим числом стартапов.

Часть задач по обработке изображений для мобильных устройств с камерами совпадает с задачами для цифровых фотоаппаратов. Основное отличие заключается в качестве объективов и в условиях съемки. Для примера можно привести задачу синтеза изображений с расширенным динамическим диапазоном (HDRI) по нескольким снимкам, полученным с разной экспозицией. В случае мобильных устройств на изображениях присутствует больший шум, кадры формируются с большим интервалом времени, и смещение камеры в пространстве также больше, что усложняет задачу получения качественных HDRI-изображений, которую при этом приходится решать на процессоре мобильного телефона. В этой связи решение, казалось бы, идентичных задач для разных устройств может различаться, что делает эти решения до сих пор востребованными на рынке.
Больший интерес, однако, представляют новые приложения, которые ранее отсутствовали на рынке. Широкий класс таких приложений для персональных мобильных устройств связан с задачами дополненной реальности, которые могут быть весьма разнообразными. Сюда относятся игровые приложения (требующие согласованного отображения виртуальных объектов поверх изображения реальной сцены при перемещении камеры), а также различные развлекательные приложения в целом, туристические приложения (распознавание достопримечательностей с выводом информации о них), а также многие другие приложения, связанные с информационным поиском и распознаванием объектов: распознавание надписей на иностранных языках с отображением их перевода, распознавание визитных карточек с автоматическим занесением информации в телефонную книгу, а также распознавание лиц с извлечением информации из телефонной книги, распознавание постеров фильмов (с заменой изображения постера на трейлер фильма) и т. д.
Системы дополненной реальности могут создаваться в виде специализированных устройств типа Google Glass, что еще больше увеличивает инновационный потенциал методов компьютерного зрения.

Таким образом, класс задач компьютерного зрения, решения которых могут быть применены в мобильных приложениях, крайне широк. Большой набор приложений есть у методов сопоставления (отождествления сопряженных точек) изображений, в том числе с оценкой трехмерной структуры сцены и определением изменения ориентации камеры и методов распознавания объектов, а также анализа лиц людей. Однако может быть предложено неограниченно большое число мобильных приложений, для которых будет требоваться разработка специализированных методов компьютерного зрения. Приведем лишь два таких примера: запись на мобильный телефон с автоматической дешифрацией партии в некоторой настольной игре и реконструкция траектории движения клюшки для гольфа при нанесении удара.
Информационный поиск и обучение
Многие задачи дополненной реальности тесно связаны с информационным поиском (так что некоторые системы, такие как Google Goggles, сложно отнести к какой-то конкретной области), который представляет существенный самостоятельный интерес.

Задачи поиска изображений по содержанию также разнообразны. Они включают сопоставление изображений при поиске изображений уникальных объектов, например архитектурных сооружений, скульптур, картин и т. д., обнаружение и распознавание на изображениях объектов классов разной степени общности (автомобилей, животных, мебели, лиц людей и т. д., а также их подклассов), категоризация сцен (город, лес, горы, побережье и т. д.). Эти задачи могут встречаться в различных приложениях - для сортировки изображений в домашних цифровых фотоальбомах, для поиска товаров по их изображениям в интернет-магазинах, для извлечения изображений в геоинформационных системах, для систем биометрической идентификации, для специализированного поиска изображений в социальных сетях (например, поиска лиц людей, привлекательных для пользователя) и т. д., вплоть до поиска изображений в Интернете.
Как уже достигнутый прогресс, так и перспективы его продолжения видны на примере конкурса Large Scale Visual Recognition Challenge , в котором количество распознаваемых классов увеличилось с 20 в 2010 г. до 200 в 2013-м.

Распознавание объектов стольких классов сейчас немыслимо без привлечения методов машинного обучения в область компьютерного зрения. Одно из крайне популярных направлений здесь - сети глубокого обучения, предназначенные для автоматического построения многоуровневых систем признаков, по которым происходит дальнейшее распознавание. Востребованность этого направления видна по фактам приобретения различных стартапов такими корпорациями, как Google и Facebook. Так, корпорацией Google в 2013 г. была куплена фирма DNNresearch, а в начале 2014 г. - стартап DeepMind. Причем за покупку последнего стартапа конкурировал и Facebook (который до этого нанял такого специалиста, как Ян Ле Кун, для руководства лабораторией, ведущей разработки в области глубокого обучения), а стоимость покупки составила $400 млн. Стоит отметить, что и упоминавшийся метод , выигравший в конкурсе по распознаванию дорожных знаков, также основан на сетях глубокого обучения.
Методы глубокого обучения требуют огромных вычислительных ресурсов, и даже для обучения распознаванию ограниченного класса объектов могут требоваться несколько дней работы на вычислительном кластере. При этом в будущем могут быть разработаны еще более мощные, но требующие еще больших вычислительных ресурсов методы.
Заключение
Мы рассмотрели лишь наиболее распространенные приложения компьютерного зрения для массового пользователя. Однако существует и множество других, менее типичных приложений. К примеру, методы компьютерного зрения могут быть использованы в микроскопии, оптической когерентной томографии, цифровой голографии. Многочисленны приложения методов обработки и анализа изображений в различных профессиональных областях - биомедицине, космической отрасли, криминалистике и т. д.

Восстановление 3D-профиля листа металла, наблюдаемого с помощью микроскопа, методом «глубина из фокусировки»
В настоящее время количество актуальных приложений компьютерного зрения продолжает расти. В частности, для решения становятся доступными задачи, связанные с анализом видеоданных. Активное развитие трехмерного телевидения расширяет заказ на системы компьютерного зрения, для создания которых не разработаны еще эффективные алгоритмы и требуются более существенные вычислительные мощности. Такой востребованной задачей является, в частности, задача конвертации видео 2D в 3D.
Неудивительно, что на переднем фронте систем компьютерного зрения продолжают активно использоваться специальные вычислительные средства. В частности, сейчас популярны графические процессоры общего назначения (GPGPU) и облачные вычисления. Однако соответствующие решения постепенно перетекают в сегмент персональных компьютеров с существенным расширением возможных приложений.
Область применения компьютерного зрения очень широка: от считывателей штрихкодов в супермаркетах до дополненной реальности. Из этой лекции вы узнаете, где используется и как работает компьютерное зрение, как выглядят изображения в цифрах, какие задачи в этой области решаются относительно легко, какие трудно, и почему.
Лекция рассчитана на старшеклассников – студентов Малого ШАДа, но и взрослые смогут почерпнуть из нее много полезного.
Возможность видеть и распознавать объекты – естественная и привычная возможность для человека. Однако для компьютера пока что – это чрезвычайно сложная задача. Сейчас предпринимаются попытки научить компьютер хотя бы толике того, что человек использует каждый день, даже не замечая того.
Наверное, чаще всего обычный человек встречается с компьютерным зрением на кассе в супермаркете. Конечно, речь идет о считывании штрихкодов. Они были разработаны специально именно таким образом, чтобы максимально упростить компьютеру процесс считывания. Но есть и более сложные задачи: считывание номеров автомобилей, анализ медицинских снимков, дефектоскопия на производстве, распознавание лиц и т.д. Активно развивается применение компьютерного зрения для создания систем дополненной реальности.
Разница между зрением человека и компьютера
Ребенок учится распознавать объекты постепенно. Он начинает осознавать, как меняется форма объекта в зависимости от его положения и освещения. В дальнейшем при распознавании объектов человек ориентируется на предыдущий опыт. За свою жизнь человек накапливает огромное количество информации, процесс обучения нейронной сети не останавливается ни на секунду. Для человека не представляет особой сложности по плоской картинке восстановить перспективу и представить себе, как бы все это выглядело в трех измерениях.Компьютеру все это дается гораздо сложнее. И в первую очередь из-за проблемы накопления опыта. Нужно собрать огромное количество примеров, что пока что не очень получается.
Кроме того, человек при распознавании объекта всегда учитывает окружение. Если выдернуть объект из привычного окружения, узнать его станет заметно труднее. Тут тоже играет роль накопленный за жизнь опыт, которого у компьютера нет.
Мальчик или девочка?
Представим, что нам нужно научиться с одного взгляда определять пол человека (одетого!) по фотографии. Для начала нужно определить факторы, которые могут указывать на принадлежность к тому или иному объекту. Кроме того, нужно собрать обучающее множество. Желательно, чтобы оно было репрезентативным. В нашем случае возьмем в качестве обучающей выборки всех присутствующих в аудитории. И попробуем на их основе найти отличительные факторы: например, длина волос, наличие бороды, макияжа и одежда (юбка или брюки). Зная, у какого процента представителей одного пола встречались те или иные факторы, мы сможем создать достаточно четкие правила: наличие тез или иных комбинаций факторов с некоей вероятностью позволит нам сказать, человек какого пола на фотографии.Машинное обучение
Конечно, это очень простой и условный пример с небольшим количеством верхнеуровневых факторов. В реальных задачах, которые ставятся перед системами компьютерного зрения, факторов гораздо больше. Определять их вручную и просчитывать зависимости – непосильная для человека задача. Поэтому в таких случаях без машинного обучения не обойтись никак. Например, можно определить несколько десятков первоначальных факторов, а также задать положительные и отрицательные примеры. А уже зависимости между этими факторами подбираются автоматически, составляется формула, которая позволяет принимать решения. Достаточно часто и сами факторы выделяются автоматически.Изображение в цифрах
Чаще всего для хранения цифровых изображений используется цветовое пространство RGB. В нем каждой из трех осей (каналов) присваивается свой цвет: красный, зеленый и синий. На каждый канал выделяется по 8 бит информации, соответственно, интенсивность цвета на каждой оси может принимать значения в диапазоне от 0 до 255. Все цвета в цифровом пространстве RGB получаются путем смешивания трех основных цветов.К сожалению, RGB не всегда хорошо подходит для анализа информации. Эксперименты показывают, что геометрическая близость цветов достаточно далека от того, как человек воспринимает близость тех или иных цветов друг к другу.
Но существуют и другие цветовые пространства. Весьма интересно в нашем контексте пространство HSV (Hue, Saturation, Value). В нем присутствует ось Value, обозначающая количество света. На него выделен отдельный канал, в отличие от RGB, где это значение нужно вычислять каждый раз. Фактически, это черно-белая версия изображения, с которой уже можно работать. Hue представляется в виде угла и отвечает за основной тон. От значения Saturation (расстояние от центра к краю) зависит насыщенность цвета.

HSV гораздо ближе к тому, как мы представляем себе цвета. Если показать человеку в темноте красный и зеленый объект, он не сможет различить цвета. В HSV происходит то же самое. Чем ниже по оси V мы продвигаемся, тем меньше становится разница между оттенками, так как снижается диапазон значений насыщенности. На схеме это выглядит как конус, на вершине которого предельно черная точка.
Цвет и свет
Почему так важно иметь данные о количестве света? В большинстве случаев в компьютерном зрении цвет не имеет никакого значения, так как не несет никакой важной информации. Посмотрим на две картинки: цветную и черно-белую. Узнать все объекты на черно-белой версии не намного сложнее, чем на цветной. Дополнительной нагрузки для нас цвет в данном случае не несет никакой, а вычислительных проблем создает великое множество. Когда мы работаем с цветной версией изображения, объем данных, грубо говоря, возводится в степень куба.
Цвет используется лишь в редких случаях, когда это наоборот позволяет упростить вычисления. Например, когда нужно детектировать лицо: проще сначала найти его возможное расположение на картинке, ориентируясь на диапазон телесных оттенков. Благодаря этому отпадает необходимость анализировать изображение целиком.
Локальные и глобальные признаки
Признаки, при помощи которых мы анализируем изображение, бывают локальными и глобальными. Глядя на эту картинку, большинство скажет, что на ней изображена красная машина:
Такой ответ подразумевает, что человек выделил на изображении объект, а значит, описал локальный признак цвета. По большому счету на картинке изображен лес, дорога и немного автомобиля. По площади автомобиль занимает меньшую часть. Но мы понимаем, что машина на этой картинке – самый важный объект. Если человеку предложить найти картинки похожие на эту, он будет в первую очередь отбирать изображения, на которых присутствует красная машина.
Детектирование и сегментация
В компьютерном зрении этот процесс называется детектированием и сегментацией. Сегментация – это разделение изображения на множество частей, связанных друг с другом визуально, либо семантически. А детектирование – это обнаружение объектов на изображении. Детектирование нужно четко отличать от распознавания. Допустим, на той же картинке с автомобилем можно детектировать дорожный знак. Но распознать его невозможно, так как он повернут к нам обратной стороной. Так же при распознавании лиц детектор может определить расположение лица, а «распознаватель» уже скажет, чье это лицо.
Дескрипторы и визуальные слова
Существует много разных подходов к распознаванию.Например, такой: на изображении сначала нужно выделить интересные точки или интересные места. Что-то отличное от фона: яркие пятна, переходы и т.д. Есть несколько алгоритмов, позволяющих это сделать.
Один из наиболее распространенных способов называется Difference of Gaussians (DoG). Размывая картинку с разным радиусом и сравнивая получившиеся результаты, можно находить наиболее контрастные фрагменты. Области вокруг этих фрагментов и являются наиболее интересными.
На картинке ниже изображено, как это примерно выглядит. Полученные данные записываются в дескрипторы.

Чтобы одинаковые дескрипторы признавались таковыми независимо от поворотов в плоскости, они разворачиваются так, чтобы самые большие векторы были повернуты в одну сторону. Делается это далеко не всегда. Но если нужно обнаружить два одинаковых объекта, расположенных в разных плоскостях.
Дескрипторы можно записывать в числовом виде. Дескриптор можно представить в виде точки в многомерном массиве. У нас на иллюстрации двумерный массив. В него попали наши дескрипторы. И мы можем их кластеризовать – разбить на группы.

Дальше мы для каждого кластера описываем область в пространстве. Когда дескриптор попадает в эту область, для нас становится важным не то, каким он был, а то, в какую из областей он попал. И дальше мы можем сравнивать изображения, определяя, сколько дескрипторов одного изображения оказались в тех же кластерах, что и дескрипторы другого изображения. Такие кластеры можно называть визуальными словами.
Чтобы находить не просто одинаковые картинки, а изображения похожих объектов, требуется взять множество изображений этого объекта и множество картинок, на которых его нет. Затем выделить из них дескрипторы и кластеризовать их. Далее нужно выяснить, в какие кластеры попали дескрипторы с изображений, на которых присутствовал нужный нам объект. Теперь мы знаем, что если дескрипторы с нового изображения попадают в те же кластеры, значит, на нем присутствует искомый объект.
Совпадение дескрипторов – еще не гарантия идентичности содержащих их объектов. Один из способов дополнительной проверки – геометрическая валидация. В этом случае проводится сравнение расположения дескрипторов относительно друг друга.
Распознавание и классификация
Для простоты представим, что мы можем разбить все изображения на три класса: архитектура, природа и портрет. В свою очередь, природу мы можем разбить на растения животных и птиц. А уже поняв, что это птица, мы можем сказать, какая именно: сова, чайка или ворона.
Разница между распознаванием и классификацией достаточно условна. Если мы нашли на картинке сову, то это скорее распознавание. Если просто птицу, то это некий промежуточный вариант. А если только природу – это определенно классификация. Т.е. разница между распознаванием и классификацией заключается в том, насколько глубоко мы прошли по дереву. И чем дальше будет продвигаться компьютерное зрение, тем ниже будет сползать граница между классификацией и распознаванием.
Давайте вернемся в детство, и вспомним фантастику. Ну, хотя бы Звездные войны, где есть такой желтый человекообразый робот. Он каким-то волшебным образом ходит и ориентируется в пространстве. По сути, у этого робота есть «глаза» и он «видит» окружающее пространство. Но как компьютеры могут что-либо видеть? Когда мы смотрим на что-то, мы понимаем, что мы видим, для нас зрительная информация осмысленна. Но подключив к компьютеру видеокамеры, мы получим лишь набор нулей и единиц, которые он с этой видеокамеры будет считывать. Как компьютеру «понять», что он «видит»? Для ответа на этот вопрос создана такая научная дисциплина, как Computer Vision (Компьютерное зрение). По сути, Computer Vision — это наука о том, как создать алгоритмы, которые анализируют изображения и ищут в них полезную информацию (информацию, которая необходима роботу для ориентации по данным, поступающим с видеокамеры). Задача компьютерного зрения является, по сути, задачей .
Существует несколько направлений и подходов в Computer Vision:
- Предобработка изображений.
- Сегментация.
- Выделение контуров.
- Нахождение особых точек.
- Нахождение объектов на изображении.
- Распознавание образов.
Разберем их более подробно.
Предобработка изображений. Как правило, перед тем как анализировать изображение, необходимо провести предварительную обработку, которая облегчит анализ. Например, удалить шумы, либо какие-то мелкие незначительные детали, которые мешают анализу, либо провести еще какую-либо обработку, которая облегчит анализ. В частности, для подавления шумов и мелких деталей используют фильтр размытия изображения.
Пример, зашумленное изображение:
После применения размытия по гауссу

Однако у него есть существенный недостаток: вместе с подавлением шумов размываются границы между областями изображение, а мелкие детали не исчезают, они просто превращаться в пятна. Для устранения данных недостатков используют медианную фильтрацию. Она хорошо справляется с импульсным шумом и удалением мелких деталей, причем, границы не размываются. Однако медианная фильтрация не справятся с гауссовым шумом.
Сегментация. Сегментация — это разделение изображение на области. Например, одна область — фон, другая конкретный объект. Или, например, есть у нас фотография, где морской пляж. Мы делим ее на области: море, пляж, небо. Для чего нужна сегментация? Ну например, у нас есть задача найти на изображении объект. Для ускорения мы ограничиваем область поиска определенным сегментом, если точно знаем, что объект может быть только в этой области. Или, например, в геоинформатике может быть задача сегментации спутниковых или аэро фотоснимков.
Пример. Вот у нас исходное изображение:

А вот его сегментация:

В данном случае при сегментации использовались текстурные признаки.
Выделение контуров. Для чего на изображении выделять контур? Давайте предположим, что нам надо решить задачу поиска на фотографии лица человека. Допустим, мы сначала попытались решить эту задачу «в лоб» — тупым перебором. Берем «квадратик» с изображением лица и попиксельно сравниваем его с изображением, перемещая квадратик попиксельно слева направо и так по каждой строке пикселей. Понятно, что так будет работать слишком долго, к тому-же, такой алгоритм найдет не любое лицо, а только одно конкретное. И то, если его чуть-чуть повернуть или изменить масштаб, то все, поиск перестанет работать. Другое дело, если у нас есть контур изображения и контур лица. Мы сможем линии контура описать каким-то иным способом, кроме растровой картинки, например, в виде списка координат его точек, в виде группы линий, описанных разными математическими формулами. Короче говоря, выделим контур, мы можем его векторизовать и производить уже не поиск растра среди растра, а векторного объекта среди векторных объектов. Это гораздо быстрее, кроме того, тогда описание объектов может быть инвариантным к поворотам и/или масштабу (то есть, мы можем находить объекты даже если они повернуты или масштабированы).
Теперь возникает вопрос: а как выделить контур? Как правило, сначала получают так называемый контурный препарат, чаще всего это градиент (скорость изменения яркости). То есть, получив градиент изображения, мы увидим белыми те области, где у нас резкие перепады яркости, и черными где яркость меняется плавно или вообще не меняется. Иными словами, все границы у нас будут выделены белыми полосами. Дальше эти белые полосы мы сужаем и получаем контур (если описать кратко что делает алгоритм получения контура). В настоящее время существует ряд стандартных алгоритмов выделения контура, например, алгоритм Кэнни, который реализован в библиотеке OpenCV.
Пример выделения контуров.
Исходное изображение:

Выделенные контуры:
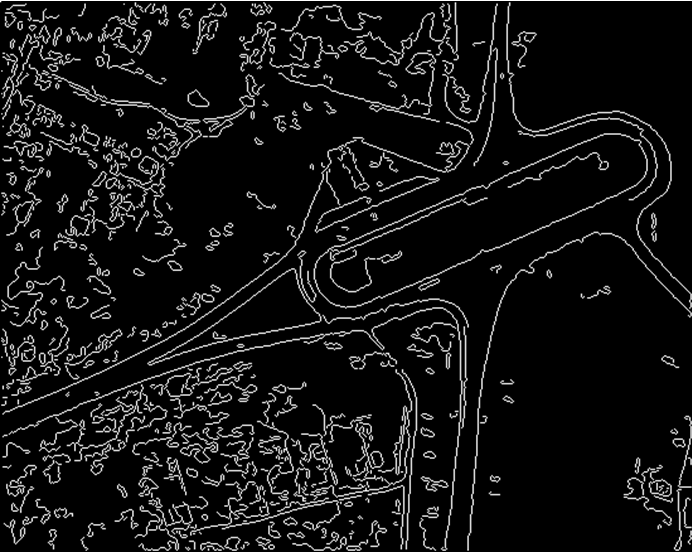
Нахождение особых точек. Другой метод анализа изображения — это нахождение на нем особых точек. В качестве особых точек могут быть, например, углы, экстремумы яркости, а также другие особенности изображения. С особыми точками можно делать примерно тоже, что и с контурами — описать в векторном виде. Например, можно описать взаимное расположение точек в виде расстояний между точками. При повороте объектов расстояние не меняется — значит, такое описание будет инвариантно к повороту. А чтобы сделать модель еще и инвариантной к масштабу, можно описать не расстояние, а отношения между расстояниями — действительно, если расстояние одной пары точек в два раза больше чем другой пары точек, о оно будет всегда в два раза больше, независимо от того, во сколько раз мы увеличили или уменьшили объект. В настоящее время существует много типовых алгоритмов нахождения особых точек, например, детектор Харриса, Моравеца, MSER, AKAZE и так далее. Многие из существующих алгоритмов нахождения особых точек реализованы в OpenCV.
Распознавание образов. Данный процесс происходит когда изображение проанализировано, на нем выделены контуры и преобразованы в векторный вид, либо найден особые точки и вычислено их взаимное расположение (либо и то и другое вместе). В общем, получена совокупность признаков, по которым и происходит определение, какие на картинке есть объекты. Для этого исполняться различные эвристические алгоритмы, например, . Вообще, как распознавать образы — это целая наука, называемая Теория распознавания образов.
Распознавание образов - это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных. При постановке задач распознавания стараются пользоваться математическим языком, стремясь — в отличие от теории искусственных нейронных сетей, где основой является получение результата путём эксперимента, — заменить эксперимент логическими рассуждениями и математическими доказательствами. Классическая постановка задачи распознавания образов: Дано множество объектов. Относительно них необходимо провести классификацию. Множество представлено подмножествами, которые называются классами. Заданы: информация о классах, описание всего множества и описание информации об объекте, принадлежность которого к определенному классу неизвестна. Требуется по имеющейся информации о классах и описании объекта установить — к какому классу относится этот объект.
Существует несколько подходов к распознаванию образов:
- Перечисление. Каждый класс задаётся путём прямого указания его членов. Такой подход используется в том случае, если доступна полная априорная информация о всех возможных объектах распознавания. Предъявляемые системе образы сравниваются с заданными описаниями представителей классов и относятся к тому классу, которому принадлежат наиболее сходные с ними образцы. Такой подход называют методом сравнения с эталоном. Он, к примеру, применим при распознавании машинопечатных символов определённого шрифта. Его недостатком является слабая устойчивость к шумам и искажениям в распознаваемых образах.
- Задание общих свойств . Класс задаётся указанием некоторых признаков, присущих всем его членам. Распознаваемый объект в таком случае не сравнивается напрямую с группой эталонных объектов. В его первичном описании выделяются значения определённого набора признаков, которые затем сравниваются с заданными признаками классов. Такой подход называется сопоставлением по признакам. Он экономичнее метода сравнения с эталоном в вопросе количества памяти, необходимой для хранения описаний классов. Кроме того, он допускает некоторую вариативность распознаваемых образов. Однако, главной сложностью является определение полного набора признаков, точно отличающих членов одного класса от членов всех остальных.
- Кластеризация. В случае, когда объекты описываются векторами признаков или измерений, класс можно рассматривать как кластер. Распознавание осуществляется на основе расчёта расстояния (чаще всего это евклидово расстояние) описания объекта до каждого из имеющихся кластеров. Если кластеры достаточно разнесены в пространстве, при распознавании хорошо работает метод оценки расстояний от рассматриваемого объекта до каждого из кластеров. Сложность распознавания возрастает, если кластеры перекрываются. Обычно это является следствием недостаточности исходной информации и может быть разрешено увеличением количества измерений объектов. Для задания исходных кластеров целесообразно использовать процедуру обучения.
Для того, чтобы провести процедуру распознавание образов, объекты нужно как-то описать. Существует также несколько способов описания объектов:
- Евклидово пространство — объекты представляются точками в евклидовом пространстве их вычисленных параметров, представление в виде набора измерений;
- Списки признаков — выявление качественных характеристик объекта и построение характеризующего вектора;
- Структурное описание — выявление структурных элементов объекта и определение их взаимосвязи.
Нахождение объектов на изображении. Задача нахождения объектов на изображении сводиться к тому, что нам необходимо найти заранее известный объект, например, лицо человека. Для этого данный объект мы описываем какими-либо признаками, и ищем на изображением объект, удовлетворяющий этим признакам. Эта задача похожа на задачу распознавания образов, но с тем лишь отличием, что тут надо не классифицировать неизвестный объект, а найти где на изображении находиться известный объект с заданными признаками. Часто к задаче нахождения объектов на изображениях предъявляют требования по быстродействию, так как это необходимо делать в режиме реального времени.
Классический пример подобных алгоритмов — распознавание лиц по методу Виола Джонсона. Хотя этот метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом, он до сих пор является основополагающим для поиска объектов на изображении в реальном времени. Основные принципы, на которых основан метод, таковы:
- Используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты;
- Используются признаки Хаара, с помощью которых происходит поиск нужного объекта (в данном контексте, лица и его черт);
- Используется бустинг (от англ. boost – улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения;
- Все признаки поступают на вход классификатора, который даёт результат «верно» либо «ложь»;
- Используются каскады признаков для быстрого отбрасывания окон, где не найдено лицо.
Скажу пару слов об интегральном изображении. Дело в том, что в задачах компьютерного зрения часто приходиться использовать метод сканирующего окна: мы двигаем окно попиксельно по всему изображению и для каждого пикселя окна выполняем определенный алгоритм. Как я уже говорил в начале статьи, такой подход работает медленно, особенно если размер скользящего окна и изображения большой. Например, если у нас размер изображения 1000 на 1000 то это будет миллион пикселей. А если скользящее окно 10 на 10 в нем 100 пикселей и алгоритм, обрабатывающий сто пикселей надо выполнить миллион раз. При получении интегрального изображения мы пробегам по картинке 1 раз и получаем матрицу, в которой каждый пиксель — это сумма яркостей прямоугольника, ограниченного этим пикселем и началом координат. Благодаря такой матрице, мы можем вычислить всего за 4 операции может вычислить сумму яркостей любого прямоугольника (хоть 10 на 10, хоть 30 на 30, хоть 100 на 50). Как правило, во многих случаях, обработка в скользящем окне как раз сводиться к вычислению суммы яркостей.
Компьютерное зрение и распознавание изображений являются неотъемлемой частью (ИИ), который за прошедшие годы обрел огромную популярность. В январе этого года состоялась выставка CES 2017, где можно было посмотреть на последние достижения в этой сфере. Вот несколько интересных примеров использования компьютерного зрения, которые можно было увидеть на выставке.
8 примеров использования компьютерного зрения
Вероника Елкина1. Беспилотные автомобили
Самые крупные стенды с компьютерным зрением принадлежат автомобильной промышленности. В конце концов, технологии беспилотных и полуавтономных автомобилей работают, во многом, благодаря компьютерному зрению.
Продукты компании NVIDIA, которая уже сделала большие шаги в области глубинного обучения, используются во многих беспилотных автомобилях. Например, суперкомпьютер NVIDIA Drive PX 2 уже служит базовой платформой для беспилотников , Volvo, Audi, BMW и Mercedes-Benz.
Технология искусственного восприятия DriveNet от NVIDIA представляет собой самообучаемое компьютерное зрение, работающее на основе нейронных сетей. С ее помощью лидары, радары, камеры и ультразвуковые датчики способны распознавать окружение, дорожную разметку, транспорт и многое другое.
3. Интерфейсы
Технологии отслеживания движения глаз с помощью компьютерного зрения используется не только в игровых ноутбуках, но и в обычных, и корпоративных компьютерах, для того чтобы ими могли управлять люди, которые не могут воспользоваться руками. Tobii Dynavox PCEye Mini представляет собой устройство размером с шариковую ручку, которое станет идеальным и незаметным аксессуаром для планшетов и ноутбуков. Также эта технология отслеживания движения глаз используется в новых игровых и обычных ноутбуках Asus и смартфонах Huawei.
Тем временем продолжает развиваться жестовое управление (технология компьютерного зрения, которое может распознавать особые движения руками). Теперь оно будет использоваться в будущих автомобилях BMW и Volkswagen.

Новый интерфейс HoloActive Touch позволяет пользователям управлять виртуальными 3D-экранами и нажимать кнопки в пространстве. Можно сказать, что он представляет собой простую версию самого настоящего голографического интерфейса Железного человека (он даже точно так же реагирует легкой вибрацией на нажатие элементов). Благодаря таким технологиям, как ManoMotion , можно будет легко добавить жестовое управление практически в любое устройство. Причем для получения контроля над виртуальным 3D-объектом с помощью жестов ManoMotion использует обычную 2D-камеру, так что вам не понадобится никакое дополнительное оборудование.
Устройство eyeSight’s Singlecue Gen 2 использует компьютерное зрение (распознавание жестов, анализ лица, определение действий) и позволяет управлять с помощью жестов телевизором, «умной» системой освещения и холодильниками.

Hayo
Краудфандинговый проект Hayo , пожалуй, является самым интересным новым интерфейсом. Эта технология позволяет создавать виртуальные средства управления по всему дому - просто подняв или опустив руку, вы можете увеличить или уменьшить громкость музыки, или же включить свет на кухне, взмахнув рукой над столешницей. Все это работает благодаря цилиндрическому устройству, использующему компьютерное зрение, а также встроенную камеру и датчики 3D, инфракрасного излучения и движения.
4. Бытовые приборы
Дорогие камеры , которые показывают, что находится внутри вашего холодильника, уже не кажутся такими революционными. Но что вы скажете о приложении, которое анализирует изображение со встроенной в холодильник камеры и сообщает, когда у вас заканчиваются определенные продукты?

Элегантное устройство FridgeCam от Smarter крепится к стенке холодильника и может определять, когда истекает срок годности, сообщать, что именно находится в холодильнике, и даже рекомендовать рецепты блюд из выбранных продуктов. Устройство продается по неожиданно доступной цене - всего за $100.
5. Цифровые вывески
Компьютерное зрение может изменить то, как выглядят баннеры и реклама в магазинах, музеях, стадионах и развлекательных парках.
На стенде Panasonic была представлена демоверсия технологии проецирования изображения на флаги. С помощью инфракрасных маркеров, невидимых для человеческого глаза, и стабилизации видео, эта технология может проецировать рекламу на висящие баннеры и даже на флаги, развевающиеся на ветру. Причем изображение будет выглядеть так, будто бы оно действительно на них напечатано.
6. Смартфоны и дополненная реальность
Многие говорили об игре как о первом массовом приложении с элементами (AR). Однако как и другие приложения, пытающиеся запрыгнуть на AR-поезд, эта игра больше использовала GPS и триангуляцию, чтобы у пользователей возникло ощущение, что объект находится прямо перед ними. Обычно в смартфонах практически не используются настоящие технологии компьютерного зрения.

Однако в ноябре Lenovo выпустила Phab2 - первый смартфон с поддержкой технологии Google Tango . Эта технология представляет собой комбинацию датчиков и ПО с компьютерным зрением, которая может распознавать изображения, видео и окружающий мир в реальном времени с помощью линзы фотокамеры.

На выставке CES Asus впервые представила ZenPhone AR - смартфон с поддержкой Tango и Daydream VR от Google. Смартфон не только может отслеживать движения, анализировать окружение и точно определять положение, но и использует процессор Qualcomm Snapdragon 821, который позволяет распределять загрузку данных компьютерного зрения. Все это помогает применять настоящие технологии дополненной реальности, которые на самом деле анализируют обстановку через камеру смартфона.
Позже в этом году выйдет Changhong H2 - первый смартфон со встроенным молекулярным сканером. Он собирает свет, который отражается от объекта и разбивается на спектр, и затем анализирует его химический состав. Благодаря программному обеспечению, использующему компьютерное зрение, полученная информация может использоваться для разных целей - от выписки лекарств и подсчета калорий до определения состояния кожи и расчета уровня упитанности.
| 15 сентября в Москве состоится конференция по большим данным Big Data Conference . В программе - бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. Следите за Big Data Conference в |
Область применения компьютерного зрения очень широка: от считывателей штрихкодов в супермаркетах до дополненной реальности. Из этой лекции вы узнаете, где используется и как работает компьютерное зрение, как выглядят изображения в цифрах, какие задачи в этой области решаются относительно легко, какие трудно, и почему.
Лекция рассчитана на старшеклассников – студентов Малого ШАДа, но и взрослые смогут почерпнуть из нее много полезного.
Возможность видеть и распознавать объекты – естественная и привычная возможность для человека. Однако для компьютера пока что – это чрезвычайно сложная задача. Сейчас предпринимаются попытки научить компьютер хотя бы толике того, что человек использует каждый день, даже не замечая того.
Наверное, чаще всего обычный человек встречается с компьютерным зрением на кассе в супермаркете. Конечно, речь идет о считывании штрихкодов. Они были разработаны специально именно таким образом, чтобы максимально упростить компьютеру процесс считывания. Но есть и более сложные задачи: считывание номеров автомобилей, анализ медицинских снимков, дефектоскопия на производстве, распознавание лиц и т.д. Активно развивается применение компьютерного зрения для создания систем дополненной реальности.
Разница между зрением человека и компьютера
Ребенок учится распознавать объекты постепенно. Он начинает осознавать, как меняется форма объекта в зависимости от его положения и освещения. В дальнейшем при распознавании объектов человек ориентируется на предыдущий опыт. За свою жизнь человек накапливает огромное количество информации, процесс обучения нейронной сети не останавливается ни на секунду. Для человека не представляет особой сложности по плоской картинке восстановить перспективу и представить себе, как бы все это выглядело в трех измерениях.Компьютеру все это дается гораздо сложнее. И в первую очередь из-за проблемы накопления опыта. Нужно собрать огромное количество примеров, что пока что не очень получается.
Кроме того, человек при распознавании объекта всегда учитывает окружение. Если выдернуть объект из привычного окружения, узнать его станет заметно труднее. Тут тоже играет роль накопленный за жизнь опыт, которого у компьютера нет.
Мальчик или девочка?
Представим, что нам нужно научиться с одного взгляда определять пол человека (одетого!) по фотографии. Для начала нужно определить факторы, которые могут указывать на принадлежность к тому или иному объекту. Кроме того, нужно собрать обучающее множество. Желательно, чтобы оно было репрезентативным. В нашем случае возьмем в качестве обучающей выборки всех присутствующих в аудитории. И попробуем на их основе найти отличительные факторы: например, длина волос, наличие бороды, макияжа и одежда (юбка или брюки). Зная, у какого процента представителей одного пола встречались те или иные факторы, мы сможем создать достаточно четкие правила: наличие тез или иных комбинаций факторов с некоей вероятностью позволит нам сказать, человек какого пола на фотографии.Машинное обучение
Конечно, это очень простой и условный пример с небольшим количеством верхнеуровневых факторов. В реальных задачах, которые ставятся перед системами компьютерного зрения, факторов гораздо больше. Определять их вручную и просчитывать зависимости – непосильная для человека задача. Поэтому в таких случаях без машинного обучения не обойтись никак. Например, можно определить несколько десятков первоначальных факторов, а также задать положительные и отрицательные примеры. А уже зависимости между этими факторами подбираются автоматически, составляется формула, которая позволяет принимать решения. Достаточно часто и сами факторы выделяются автоматически.Изображение в цифрах
Чаще всего для хранения цифровых изображений используется цветовое пространство RGB. В нем каждой из трех осей (каналов) присваивается свой цвет: красный, зеленый и синий. На каждый канал выделяется по 8 бит информации, соответственно, интенсивность цвета на каждой оси может принимать значения в диапазоне от 0 до 255. Все цвета в цифровом пространстве RGB получаются путем смешивания трех основных цветов.К сожалению, RGB не всегда хорошо подходит для анализа информации. Эксперименты показывают, что геометрическая близость цветов достаточно далека от того, как человек воспринимает близость тех или иных цветов друг к другу.
Но существуют и другие цветовые пространства. Весьма интересно в нашем контексте пространство HSV (Hue, Saturation, Value). В нем присутствует ось Value, обозначающая количество света. На него выделен отдельный канал, в отличие от RGB, где это значение нужно вычислять каждый раз. Фактически, это черно-белая версия изображения, с которой уже можно работать. Hue представляется в виде угла и отвечает за основной тон. От значения Saturation (расстояние от центра к краю) зависит насыщенность цвета.
HSV гораздо ближе к тому, как мы представляем себе цвета. Если показать человеку в темноте красный и зеленый объект, он не сможет различить цвета. В HSV происходит то же самое. Чем ниже по оси V мы продвигаемся, тем меньше становится разница между оттенками, так как снижается диапазон значений насыщенности. На схеме это выглядит как конус, на вершине которого предельно черная точка.
Цвет и свет
Почему так важно иметь данные о количестве света? В большинстве случаев в компьютерном зрении цвет не имеет никакого значения, так как не несет никакой важной информации. Посмотрим на две картинки: цветную и черно-белую. Узнать все объекты на черно-белой версии не намного сложнее, чем на цветной. Дополнительной нагрузки для нас цвет в данном случае не несет никакой, а вычислительных проблем создает великое множество. Когда мы работаем с цветной версией изображения, объем данных, грубо говоря, возводится в степень куба.
Цвет используется лишь в редких случаях, когда это наоборот позволяет упростить вычисления. Например, когда нужно детектировать лицо: проще сначала найти его возможное расположение на картинке, ориентируясь на диапазон телесных оттенков. Благодаря этому отпадает необходимость анализировать изображение целиком.
Локальные и глобальные признаки
Признаки, при помощи которых мы анализируем изображение, бывают локальными и глобальными. Глядя на эту картинку, большинство скажет, что на ней изображена красная машина:
Такой ответ подразумевает, что человек выделил на изображении объект, а значит, описал локальный признак цвета. По большому счету на картинке изображен лес, дорога и немного автомобиля. По площади автомобиль занимает меньшую часть. Но мы понимаем, что машина на этой картинке – самый важный объект. Если человеку предложить найти картинки похожие на эту, он будет в первую очередь отбирать изображения, на которых присутствует красная машина.
Детектирование и сегментация
В компьютерном зрении этот процесс называется детектированием и сегментацией. Сегментация – это разделение изображения на множество частей, связанных друг с другом визуально, либо семантически. А детектирование – это обнаружение объектов на изображении. Детектирование нужно четко отличать от распознавания. Допустим, на той же картинке с автомобилем можно детектировать дорожный знак. Но распознать его невозможно, так как он повернут к нам обратной стороной. Так же при распознавании лиц детектор может определить расположение лица, а «распознаватель» уже скажет, чье это лицо.
Дескрипторы и визуальные слова
Существует много разных подходов к распознаванию.Например, такой: на изображении сначала нужно выделить интересные точки или интересные места. Что-то отличное от фона: яркие пятна, переходы и т.д. Есть несколько алгоритмов, позволяющих это сделать.
Один из наиболее распространенных способов называется Difference of Gaussians (DoG). Размывая картинку с разным радиусом и сравнивая получившиеся результаты, можно находить наиболее контрастные фрагменты. Области вокруг этих фрагментов и являются наиболее интересными.
На картинке ниже изображено, как это примерно выглядит. Полученные данные записываются в дескрипторы.
Чтобы одинаковые дескрипторы признавались таковыми независимо от поворотов в плоскости, они разворачиваются так, чтобы самые большие векторы были повернуты в одну сторону. Делается это далеко не всегда. Но если нужно обнаружить два одинаковых объекта, расположенных в разных плоскостях.
Дескрипторы можно записывать в числовом виде. Дескриптор можно представить в виде точки в многомерном массиве. У нас на иллюстрации двумерный массив. В него попали наши дескрипторы. И мы можем их кластеризовать – разбить на группы.
Дальше мы для каждого кластера описываем область в пространстве. Когда дескриптор попадает в эту область, для нас становится важным не то, каким он был, а то, в какую из областей он попал. И дальше мы можем сравнивать изображения, определяя, сколько дескрипторов одного изображения оказались в тех же кластерах, что и дескрипторы другого изображения. Такие кластеры можно называть визуальными словами.
Чтобы находить не просто одинаковые картинки, а изображения похожих объектов, требуется взять множество изображений этого объекта и множество картинок, на которых его нет. Затем выделить из них дескрипторы и кластеризовать их. Далее нужно выяснить, в какие кластеры попали дескрипторы с изображений, на которых присутствовал нужный нам объект. Теперь мы знаем, что если дескрипторы с нового изображения попадают в те же кластеры, значит, на нем присутствует искомый объект.
Совпадение дескрипторов – еще не гарантия идентичности содержащих их объектов. Один из способов дополнительной проверки – геометрическая валидация. В этом случае проводится сравнение расположения дескрипторов относительно друг друга.
Распознавание и классификация
Для простоты представим, что мы можем разбить все изображения на три класса: архитектура, природа и портрет. В свою очередь, природу мы можем разбить на растения животных и птиц. А уже поняв, что это птица, мы можем сказать, какая именно: сова, чайка или ворона.
Разница между распознаванием и классификацией достаточно условна. Если мы нашли на картинке сову, то это скорее распознавание. Если просто птицу, то это некий промежуточный вариант. А если только природу – это определенно классификация. Т.е. разница между распознаванием и классификацией заключается в том, насколько глубоко мы прошли по дереву. И чем дальше будет продвигаться компьютерное зрение, тем ниже будет сползать граница между классификацией и распознаванием.