Zainteresowanie wizją komputerową było jednym z pierwszych w tej dziedzinie sztuczna inteligencja wraz z zadaniami, takimi jak automatyczne dowodzenie twierdzeń i gry umysłowe. Nawet architektura pierwszego sztucznego sieć neuronowa- perceptron - zaproponował Frank Rosenblatt, bazując na analogii z siatkówką, a jego badanie przeprowadzono na przykładzie problemu rozpoznawania obrazu postaci.
Znaczenie problemu widzenia nigdy nie było kwestionowane, ale jednocześnie jego złożoność została znacząco niedoceniona. Na przykład przypadek, kiedy w 1966 roku jeden z założycieli dziedziny sztucznej inteligencji, Marvin Minsky, nie zamierzał sam rozwiązać problemu sztucznego widzenia, ale polecił to jednemu ze studentów, aby to zrobił następnego lata, stał się legendą w jego wykładniczy charakter. Jednocześnie znacznie więcej czasu poświęcono na stworzenie programu grającego na poziomie arcymistrza w szachach. Jednak teraz jest oczywiste, że stworzenie programu, który bije człowieka w szachy jest łatwiejsze niż stworzenie adaptacyjnego systemu kontroli z komputerowym podsystemem wizyjnym, który mógłby po prostu zmienić układ szachów na dowolnej rzeczywistej szachownicy.
Postęp w dziedzinie widzenia komputerowego jest determinowany przez dwa czynniki: rozwój teorii, metod oraz rozwój sprzętu. Przez długi czas teoria i badania naukowe wyprzedzały krzywą praktyczne użycie komputerowe systemy wizyjne. Warunkowo można wyróżnić kilka etapów rozwoju teorii.
- Do lat 70. ukształtował się główny aparat pojęciowy w dziedzinie przetwarzania obrazu, który jest podstawą do badania problemów ze wzrokiem. Zidentyfikowano również główne zadania charakterystyczne dla widzenia maszynowego, związane z oceną fizycznych parametrów sceny (zasięg, prędkość ruchu, odbicia powierzchni itp.) na podstawie obrazów, choć wiele z tych zadań nadal brało pod uwagę bardzo uproszczone sformułowanie „świata kostek zabawek”.
- Do lat 80. ukształtowała się teoria poziomów reprezentacji obrazów w metodach ich analizy. Książka Davida Marra Wizja. Informacyjne podejście do badania reprezentacji i przetwarzania obrazów wizualnych.
- Do lat 90. ukształtowała się systematyczna idea podejść do rozwiązywania głównych, klasycznych już problemów widzenia maszynowego.
- Od połowy lat 90. nastąpiło przejście do tworzenia i badania wielkoskalowych systemów widzenia komputerowego przeznaczonych do pracy w różnych warunkach naturalnych.
- Obecny etap jest najciekawszy w rozwoju metod automatycznego konstruowania reprezentacji obrazu w systemach rozpoznawania obrazu i komputerowych systemach wizyjnych w oparciu o zasady uczenia maszynowego.
Jednocześnie aplikacje były ograniczone zasobami obliczeniowymi. Rzeczywiście, aby wykonać nawet najprostsze przetwarzanie obrazu, musisz wyświetlić wszystkie jego piksele przynajmniej raz (i zwykle więcej niż raz). Aby to zrobić, trzeba wykonać co najmniej setki tysięcy operacji na sekundę, co przez długi czas było niemożliwe i wymagało uproszczeń.
Np. do automatycznego rozpoznawania detali w przemyśle można zastosować czarny przenośnik taśmowy, eliminując konieczność oddzielania obiektu od tła, czy skanując poruszający się obiekt linią fotodiod ze specjalnym oświetleniem, które już na poziomie Formowanie sygnału zapewniało wybór niezmiennych cech do rozpoznania bez stosowania skomplikowanych metod analizy informacji. W optoelektronicznych systemach do śledzenia i rozpoznawania celów zastosowano fizyczne szablony, umożliwiające „sprzętowi” wykonywanie spójnego filtrowania. Niektóre z tych rozwiązań były pomysłowe z inżynierskiego punktu widzenia, ale miały zastosowanie tylko do problemów o niskiej niepewności a priori, a zatem miały w szczególności słabą przenośność do nowych problemów.
Nic dziwnego, że w latach 70. nastąpił również szczyt zainteresowania obliczeniami optycznymi w przetwarzaniu obrazu. Dzięki nim stało się możliwe mały zestaw metody (głównie korelacyjne) o ograniczonych własnościach niezmienności, ale w bardzo wydajny sposób.
Stopniowo, dzięki wzrostowi wydajności procesorów (a także rozwojowi cyfrowych kamer wideo), sytuacja uległa zmianie. Przełamanie progu wydajności wymaganego do wykonania użytecznego przetwarzania obrazu w rozsądnym czasie utorowało drogę lawinie aplikacji komputerowego widzenia. Należy jednak od razu podkreślić, że przejście to nie było natychmiastowe i trwa do dziś.
Po pierwsze, powszechnie stosowane algorytmy przetwarzania obrazu stały się dostępne dla specjalnych procesorów – cyfrowych procesorów sygnałowych (DSP) i układów logicznych programowalnych w terenie (FPGA), które często są współużytkowane i nadal są szeroko stosowane w systemach pokładowych i przemysłowych.

Jednak metody widzenia komputerowego były naprawdę szeroko stosowane dopiero niespełna dziesięć lat temu, z osiągnięciem odpowiedniego poziomu wydajności procesora w komputery mobilne. Tym samym w zakresie praktycznego zastosowania komputerowych systemów wizyjnych przeszło szereg etapów: etap indywidualnego rozwiązania (zarówno sprzętowego, jak i algorytmowego) konkretnych zadań; etap aplikacyjny w dziedzinach zawodowych (zwłaszcza w przemyśle i obronności) z wykorzystaniem specjalnych procesorów, wyspecjalizowanych systemów obrazowania i algorytmów zaprojektowanych do pracy w warunkach niskiej niepewności a priori, jednak rozwiązania te umożliwiły skalowanie; i etap masowej aplikacji.
Jak widać, system wizyjny maszyn składa się z następujących głównych elementów:

Najszerzej stosowane są systemy widzenia maszynowego, które jako pierwsze dwa komponenty wykorzystują standardowe kamery i komputery (termin „wizja komputerowa” jest bardziej odpowiednia dla takich systemów, chociaż nie ma wyraźnego rozdziału między pojęciami widzenia maszynowego i widzenia komputerowego ). Jednak oczywiście inne systemy wizyjne maszyn są nie mniej ważne. Jest to wybór „niestandardowych” metod obrazowania (w tym zastosowanie zakresów widmowych innych niż widzialne, promieniowanie koherentne, oświetlenie strukturalne, urządzenia hiperspektralne, czas przelotu, kamery dookólne i szybkie, teleskopy i mikroskopy itp. .) co znacznie rozszerza możliwości systemów widzenia maszynowego. O ile systemy widzenia maszynowego znacznie ustępują ludzkiemu wzrokowi pod względem możliwości wsparcia algorytmicznego, o tyle znacznie przewyższają możliwości pozyskiwania informacji o obserwowanych obiektach. Problematyka tworzenia obrazu stanowi jednak samodzielny obszar, a metody pracy z obrazami uzyskanymi za pomocą różnych sensorów są tak różnorodne, że ich przegląd wykracza poza zakres tego artykułu. W związku z tym ograniczymy się do przeglądu komputerowych systemów wizyjnych przy użyciu konwencjonalnych kamer.

Zastosowanie w robotyce
Robotyka to tradycyjny obszar zastosowań widzenia maszynowego. Jednak gros floty robotów przez długi czas spadał na przemysł, gdzie detekcja robotów nie była zbyteczna, ale dzięki dobrze kontrolowanym warunkom (niski niedeterminizm otoczenia) wysokospecjalistyczne rozwiązania okazały się możliwe, w tym do zadań widzenia maszynowego. Ponadto zastosowania przemysłowe pozwoliły na zastosowanie drogiego sprzętu, w tym systemów optycznych i obliczeniowych.
Pod tym względem istotne jest (choć nie tylko związane z komputerowymi systemami wizyjnymi), że udział floty robotów przypisywanych robotom przemysłowym spadł poniżej 50% dopiero na początku XXI wieku. Zaczęła się rozwijać robotyka przeznaczona dla masowego odbiorcy. W przypadku robotów domowych, w przeciwieństwie do robotów przemysłowych, krytyczny jest koszt i czas. żywotność baterii, co oznacza korzystanie z mobilnych i wbudowanych systemów procesorowych. Jednocześnie takie roboty muszą funkcjonować w środowiskach niedeterministycznych. Na przykład w przemyśle od dawna (i do dziś) znaki fotogrametryczne naklejane na obiekty tablic obserwacyjnych lub kalibracyjnych są wykorzystywane do rozwiązywania problemów określania parametrów wewnętrznych i orientacji zewnętrznej kamer. Oczywiście konieczność naklejania użytkownikowi takich etykiet na elementach wyposażenia wnętrz znacznie pogorszyłaby walory konsumenckie robotów domowych. Nic dziwnego, że rynek robotów domowych czekał na początek swojego szybkiego rozwoju do pewnego poziomu technologicznego, co nastąpiło pod koniec lat 90-tych.
Punktem wyjścia tego wydarzenia może być wydanie pierwszej wersji robota AIBO (Sony), który mimo stosunkowo wysoka cena(2500 dolarów), był bardzo poszukiwany. Pierwsza partia tych robotów w ilości 5000 sztuk została wyprzedana w Internecie w 20 minut, druga partia (również w 1999 roku) w 17 sekund, a potem sprzedaż wyniosła około 20 000 sztuk rocznie.
Również pod koniec lat 90. pojawiły się w masowej produkcji urządzenia, które można by nazwać robotami domowymi w pełnym tego słowa znaczeniu. Najbardziej typowymi autonomicznymi robotami domowymi są zrobotyzowane odkurzacze. Pierwszym modelem wydanym w 2002 roku przez iRobot była Roomba. Potem pojawiły się roboty odkurzające produkowane przez LG Electronics, Samsung itp. Do 2008 r. łączna sprzedaż robotów odkurzających na świecie wyniosła ponad pół miliona egzemplarzy rocznie.
Znamienne jest, że pierwsze odkurzacze zrobotyzowane wyposażone w komputerowe systemy wizyjne pojawiły się dopiero w 2006 roku procesory mobilne typ rodziny ARM o częstotliwości 200 MHz umożliwił uzyskanie porównania obrazów scen trójwymiarowych w pomieszczeniach w oparciu o deskryptory niezmiennicze Kluczowe punkty w celu lokalizacji sensorycznej robota z częstotliwością ok. 5 klatek/s. Wykorzystanie wizji do określenia lokalizacji robota stało się ekonomicznie uzasadnione, choć do niedawna producenci woleli wykorzystywać do tego celu sonary.
Dalsza poprawa wydajności procesorów mobilnych pozwala nam stawiać nowe wyzwania przed komputerowymi systemami wizyjnymi w robotach domowych, których liczba jest już sprzedawana na całym świecie w milionach egzemplarzy rocznie. Oprócz zadań nawigacyjnych od robotów przeznaczonych do użytku osobistego mogą być wymagane rozwiązywanie problemów rozpoznawania ludzi i ich emocji na podstawie twarzy, rozpoznawania gestów, przedmiotów mebli, w tym sztućców i naczyń, ubrań, zwierząt itp., w zależności od rodzaju zadań rozwiązany przez robota. Wiele z tych zadań jest dalekich od kompletne rozwiązanie i są obiecujące z innowacyjnego punktu widzenia.

Współczesna robotyka wymaga więc rozwiązania szerokiego zakresu problemów widzenia komputerowego, w tym w szczególności:
- zestaw zadań związanych z orientacją w przestrzeni zewnętrznej (np. zadanie jednoczesnej lokalizacji i mapowania - Symultaniczna Lokalizacja i Mapowanie, SLAM), wyznaczanie odległości do obiektów itp.;
- zadania rozpoznawania różnych obiektów i ogólnej interpretacji scen;
- zadania wykrywania ludzi, rozpoznawania ich twarzy i analizowania emocji.
Systemy wspomagania kierowcy
Oprócz robotów domowych, techniki widzenia komputerowego znalazły szerokie zastosowanie w systemach wspomagania kierowcy. W latach 90. aktywnie prowadzono prace nad wykrywaniem oznaczeń, przeszkód na drodze, rozpoznawaniem znaków itp. Osiągnęli jednak wystarczający poziom (zarówno pod względem dokładności i niezawodności samych metod, jak i pod względem wydajności procesorów zdolnych do wykonywania odpowiednich metod w czasie rzeczywistym), które osiągnęli głównie w ostatniej dekadzie.

Godnym uwagi przykładem są techniki stereowizyjne wykorzystywane do wykrywania przeszkód na drodze. Metody te mogą być bardzo krytyczne pod względem niezawodności, dokładności i wydajności. W szczególności w celu wykrycia pieszych może być konieczne zbudowanie gęstej mapy zasięgu w skali zbliżonej do czasu rzeczywistego. Metody te mogą wymagać setek operacji na piksel i dokładności osiąganej przy rozmiarach obrazu co najmniej megapiksela, czyli setek milionów operacji na klatkę (kilka miliardów lub więcej operacji na sekundę).
Warto zauważyć, że ogólny postęp w dziedzinie widzenia komputerowego nie jest bynajmniej związany wyłącznie z rozwojem sprzętu. Ta ostatnia otwiera jedynie możliwości wykorzystania kosztownych obliczeniowo metod przetwarzania obrazu, ale same te metody również wymagają rozwoju. W ciągu ostatnich 10–15 lat skutecznie wykorzystano metody porównywania obrazów trójwymiarowych scen, metody odtwarzania gęstych map zasięgu w oparciu o widzenie stereo, metody wykrywania i rozpoznawania twarzy itp. Ogólne zasady rozwiązania odpowiadających im problemów za pomocą tych metod nie uległy zmianie, ale zostały wzbogacone o szereg nietrywialnych szczegółów technicznych i sztuczek matematycznych, które sprawiły, że metody te odniosły sukces.
Wracając do systemów wspomagania kierowcy, nie można nie wspomnieć o nowoczesnych metodach wykrywania pieszych, w szczególności opartych na zorientowanych histogramach nachylenia. Nowoczesne metody uczenia maszynowego, które zostaną omówione później, po raz pierwszy pozwoliły komputerowi lepszy niż mężczyzna rozwiązać tak dość ogólne zadanie wizualne, jak rozpoznawanie znaków drogowych, ale nie poprzez użycie specjalne środki tworzenie obrazu, ale dzięki algorytmom rozpoznawania, które otrzymały dokładnie te same informacje co osoba.
Jednym ze znaczących osiągnięć technicznych był autonomiczny samochód Google, który jednak oprócz kamery wykorzystuje bogaty zestaw czujników, a także nie sprawdza się na nieznanych (nie sfilmowanych wcześniej) drogach i w złych warunkach pogodowych.
Dlatego systemy wspomagania kierowcy wymagają rozwiązania różnych problemów z widzeniem komputerowym, w tym:
- widzenie stereo;
- wykrywanie przeszkód na drogach;
- rozpoznawanie znaków drogowych, oznaczeń, pieszych i samochodów;
- zadania, również wymagające wzmianki, związane z monitorowaniem stanu kierowcy.
Aplikacje mobilne
Jeszcze bardziej masywne w porównaniu z robotami domowymi i systemami wspomagania kierowcy są zadania widzenia komputerowego na potrzeby osobiste urządzenia mobilne, takich jak smartfony, tablety itp. W szczególności liczba telefonów komórkowych stale rośnie i już prawie przekroczyła populację Ziemi. Jednocześnie większość telefonów jest obecnie produkowana z aparatami. W 2009 roku liczba takich telefonów przekroczyła miliard, tworząc kolosalny rynek systemów obrazowania i wizji komputerowej, który jest daleki od nasycenia, pomimo licznych projektów badawczo-rozwojowych prowadzonych zarówno przez samych producentów urządzeń mobilnych, jak i przez dużą liczbę start-upów ...

Część zadań przetwarzania obrazu dla urządzeń mobilnych z kamerami jest taka sama jak dla aparaty cyfrowe. Główna różnica polega na jakości soczewek i warunkach fotografowania. Przykładem jest zadanie syntezy obrazów o wysokim zakresie dynamiki (HDRI) z kilku obrazów wykonanych przy różnych ekspozycjach. W przypadku urządzeń mobilnych na obrazach jest więcej szumu, klatki powstają z dużym interwałem czasowym, a także większe jest przesunięcie kamery w przestrzeni, co komplikuje zadanie uzyskania wysokiej jakości obrazów HDRI, co w tym przypadku musi być rozwiązany na procesorze telefonu komórkowego. W związku z tym rozwiązanie pozornie identycznych problemów dla różne urządzenia mogą się różnić, co sprawia, że rozwiązania te wciąż są poszukiwane na rynku.
Większym zainteresowaniem cieszą się jednak nowe aplikacje, które wcześniej nie były dostępne na rynku. Szeroka klasa takich aplikacji na osobiste urządzenia mobilne wiąże się z zadaniami rozszerzonej rzeczywistości, które mogą być bardzo różnorodne. Obejmuje to aplikacje do gier (wymagające spójnego wyświetlania wirtualnych obiektów na rzeczywistej scenie podczas ruchu kamery), a także różne aplikacje rozrywkowe w ogóle, aplikacje podróżne (rozpoznawanie punktów zainteresowania z informacjami o nich), a także wiele innych aplikacji związanych z wyszukiwaniem informacji i rozpoznawaniem obiektów: rozpoznawanie napisów w językach obcych z wyświetleniem ich tłumaczenia, rozpoznawanie wizytówek z automatycznym wprowadzaniem informacji do książki telefonicznej, a także rozpoznawanie twarzy z wyodrębnianiem informacji z książka telefoniczna, rozpoznawanie plakatu filmowego (zastąpienie obrazu plakatu zwiastunem filmu) itp.
Systemy rzeczywistości rozszerzonej mogą być tworzone w postaci specjalistycznych urządzeń, takich jak Google Glass, co dodatkowo zwiększa potencjał innowacyjny metod komputerowego widzenia.

Tym samym klasa problemów widzenia komputerowego, których rozwiązania można zastosować w aplikacjach mobilnych, jest niezwykle szeroka. Metody dopasowywania (identyfikacji sprzężonych punktów) obrazów mają szerokie zastosowanie, m.in. do oceny trójwymiarowej struktury sceny i określenia zmian orientacji kamery oraz metod rozpoznawania obiektów, a także do analizy twarzy ludzi. Jednak nieograniczona liczba aplikacje mobilne, co będzie wymagało opracowania specjalistycznych metod widzenia komputerowego. Oto tylko dwa takie przykłady: telefon komórkowy z automatycznym dekodowaniem gry w jakiejś grze planszowej i rekonstrukcją trajektorii kija golfowego podczas uderzenia.
Pozyskiwanie i uczenie się informacji
Wiele zadań w rzeczywistości rozszerzonej jest ściśle związanych z wyszukiwaniem informacji (więc niektóre systemy, takie jak Gogle Google, trudno przypisać do konkretnego obszaru), co ma istotne znaczenie niezależne.

Różnorodne są również zadania wyszukiwania obrazów po treści. Obejmują one dopasowanie obrazu przy wyszukiwaniu obrazów unikalnych obiektów, takich jak obiekty architektoniczne, rzeźby, obrazy itp., wykrywanie i rozpoznawanie na obrazach obiektów klas o różnym stopniu ogólności (samochody, zwierzęta, meble, twarze ludzi itp.). , a także ich podklasy), kategoryzację scen (miasto, las, góry, wybrzeże itp.). Zadania te można znaleźć w różnych zastosowaniach - do sortowania zdjęć w cyfrowych albumach domowych ze zdjęciami, do wyszukiwania produktów po ich zdjęciach w sklepach internetowych, do wyodrębniania zdjęć w systemach informacji geograficznej, do systemów identyfikacja biometryczna, do specjalistycznego wyszukiwania obrazów w w sieciach społecznościowych(na przykład wyszukiwanie twarzy osób atrakcyjnych dla użytkownika) itp., aż do wyszukiwania obrazów w Internecie.
Zarówno poczyniony już postęp, jak i perspektywy jego kontynuacji widać na przykładzie Large Scale Visual Recognition Challenge, w którym liczba uznanych klas wzrosła z 20 w 2010 roku do 200 w 2013 roku.

Rozpoznawanie obiektów tak wielu klas jest obecnie nie do pomyślenia bez zaangażowania metod uczenia maszynowego z zakresu widzenia komputerowego. Jednym z niezwykle popularnych obszarów są sieci uczenia głębokiego zaprojektowane do automatycznego budowania wielopoziomowych systemów funkcji do dalszego rozpoznawania. Popyt na ten kierunek widać po faktach przejmowania różnych startupów przez korporacje takie jak Google czy Facebook. Tak więc w 2013 roku Google kupił DNNresearch, a na początku 2014 roku startup DeepMind. Co więcej, Facebook rywalizował także o zakup ostatniego startupu (który wcześniej zatrudnił takiego specjalistę jak Jan Le Kuhn do prowadzenia laboratorium prowadzącego rozwój w zakresie głębokiego uczenia), a koszt zakupu wyniósł 400 mln USD. zauważając, że wspomniana metoda, która zwyciężyła w konkursie rozpoznawania znaków drogowych, również opiera się na sieciach głębokiego uczenia się.
Metody uczenia głębokiego wymagają ogromnych zasobów obliczeniowych, a nawet nauka rozpoznawania ograniczonej klasy obiektów może zająć kilka dni pracy w klastrze obliczeniowym. Jednocześnie w przyszłości można opracować jeszcze bardziej zaawansowane metody, ale wymagające jeszcze większych zasobów obliczeniowych.
Wniosek
Rozważaliśmy tylko najczęstsze aplikacje komputerowej wizji dla masowego użytkownika. Istnieje jednak wiele innych, mniej typowych zastosowań. Na przykład metody widzenia komputerowego mogą być stosowane w mikroskopii, optycznej tomografii koherentnej, holografii cyfrowej. Istnieje wiele zastosowań metod przetwarzania i analizy obrazów w różnych dziedzinach zawodowych - biomedycynie, przemyśle kosmicznym, kryminalistyce itp.

Rekonstrukcja profilu 3D blachy obserwowanej pod mikroskopem metodą „głębi nieostrości”
Obecnie liczba odpowiednich zastosowań wizji komputerowej stale rośnie. W szczególności do rozwiązania stają się zadania związane z analizą danych wideo. Aktywny rozwój telewizji trójwymiarowej rozszerza zamówienie na komputerowe systemy wizyjne, do stworzenia których skuteczne algorytmy nie zostały jeszcze opracowane i potrzebne są bardziej merytoryczne. moc obliczeniowa. Tak wymagającym zadaniem jest w szczególności konwersja wideo 2D do 3D.
Nic dziwnego, że na czele komputerowych systemów wizyjnych nadal aktywnie wykorzystywane są specjalne narzędzia komputerowe. W szczególności teraz popularny GPU ogólny cel(GPGPU) i Chmura obliczeniowa. Jednak odpowiednie rozwiązania stopniowo napływają do segmentu komputery osobiste ze znacznym rozszerzeniem możliwych zastosowań.
Zakres wizji komputerowej jest bardzo szeroki: od czytników kodów kreskowych w supermarketach po rozszerzoną rzeczywistość. Na tym wykładzie dowiesz się, gdzie i jak działa wizja komputerowa, jak wyglądają obrazy cyfrowe, jakie zadania w tym obszarze są stosunkowo łatwe do rozwiązania, a które trudne i dlaczego.
Wykład przeznaczony jest dla uczniów szkół ponadgimnazjalnych - uczniów Małego SHAD, ale dorośli mogą się z niego nauczyć także wielu przydatnych rzeczy.
Zdolność widzenia i rozpoznawania przedmiotów jest dla człowieka naturalną i nawykową możliwością. Jednak dla komputera do tej pory – jest to niezwykle trudne zadanie. Obecnie podejmowane są próby nauczenia komputera przynajmniej ułamka tego, czego człowiek używa na co dzień, nawet tego nie zauważając.
Prawdopodobnie najczęściej zwykły człowiek styka się z wizją komputerową przy kasie w supermarkecie. Oczywiście, rozmawiamy o odczytywaniu kodów kreskowych. Zostały one specjalnie zaprojektowane w taki sposób, aby proces odczytu był jak najłatwiejszy dla komputera. Ale są też bardziej złożone zadania: odczytywanie numerów samochodów, analiza obrazów medycznych, wykrywanie wad w produkcji, rozpoznawanie twarzy itp. Aktywnie rozwija się wykorzystanie wizji komputerowej do tworzenia systemów rzeczywistości rozszerzonej.
Różnica między widzeniem ludzkim a komputerowym
Dziecko uczy się stopniowo rozpoznawać przedmioty. Zaczyna zdawać sobie sprawę, jak zmienia się kształt przedmiotu w zależności od jego położenia i oświetlenia. W przyszłości, rozpoznając przedmioty, osoba skupia się na wcześniejszych doświadczeniach. Podczas swojego życia człowiek gromadzi ogromną ilość informacji, proces uczenia się sieci neuronowej nie zatrzymuje się ani na sekundę. Nie jest szczególnie trudno przywrócić perspektywę z płaskiego obrazu i wyobrazić sobie, jak to wszystko wygląda w trzech wymiarach.Wszystko to jest znacznie trudniejsze dla komputera. A przede wszystkim z powodu problemu akumulacji doświadczenia. Konieczne jest zebranie ogromnej liczby przykładów, co do tej pory nie jest zbyt udane.
Ponadto, rozpoznając obiekt, osoba zawsze bierze pod uwagę środowisko. Jeśli wyciągniesz obiekt ze znanego otoczenia, rozpoznanie go stanie się zauważalnie trudniejsze. Tutaj również rolę odgrywa doświadczenie nagromadzone przez całe życie, którego komputer nie posiada.
Chłopiec czy dziewczyna?
Wyobraź sobie, że musimy nauczyć się określać płeć osoby (ubranej!) na podstawie zdjęcia na pierwszy rzut oka. Najpierw musisz określić czynniki, które mogą wskazywać na przynależność do konkretnego obiektu. Dodatkowo musisz zebrać zestaw treningowy. Pożądane jest, aby był reprezentatywny. W naszym przypadku jako próbkę szkoleniową weźmiemy wszystkich obecnych na widowni. I spróbujmy na ich podstawie znaleźć wyróżniki: na przykład długość włosów, obecność brody, makijaż i ubiór (spódnica lub spodnie). Wiedząc, jaki procent przedstawicieli tej samej płci spotkał określone czynniki, będziemy w stanie stworzyć dość jasne reguły: obecność tych lub innych kombinacji czynników z pewnym prawdopodobieństwem pozwoli nam powiedzieć, jakiej płci jest dana osoba na zdjęciu.Nauczanie maszynowe
Oczywiście jest to bardzo proste i przykład warunkowy z kilkoma najważniejszymi czynnikami. W rzeczywistych zadaniach stawianych przed komputerowymi systemami wizyjnymi jest o wiele więcej czynników. Określanie ich ręcznie i obliczanie zależności jest dla człowieka zadaniem niewykonalnym. Dlatego w takich przypadkach uczenie maszynowe jest niezbędne. Na przykład można zdefiniować kilkadziesiąt czynników początkowych, a także podać przykłady pozytywne i negatywne. I już zależności między tymi czynnikami są wybierane automatycznie, powstaje formuła, która pozwala podejmować decyzje. Dość często same czynniki są przydzielane automatycznie.Obraz w liczbach
Najczęściej używaną przestrzenią kolorów dla obrazów cyfrowych jest RGB. W nim każdej z trzech osi (kanałów) przypisany jest własny kolor: czerwony, zielony i niebieski. Każdemu kanałowi przydzielone jest odpowiednio 8 bitów informacji, intensywność kolorów na każdej osi może przyjmować wartości z zakresu od 0 do 255. Wszystkie kolory w przestrzeni cyfrowej RGB uzyskuje się poprzez zmieszanie trzech kolorów podstawowych.Niestety, RGB nie zawsze dobrze nadaje się do analizy informacji. Eksperymenty pokazują, że geometryczna bliskość kolorów jest dość daleka od tego, jak osoba postrzega bliskość niektórych kolorów do siebie.
Ale są też inne przestrzenie kolorów. Przestrzeń HSV (Hue, Saturation, Value) jest bardzo interesująca w naszym kontekście. Posiada oś Wartość wskazującą ilość światła. Przydzielony jest do niego osobny kanał, w przeciwieństwie do RGB, gdzie ta wartość musi być każdorazowo obliczana. W rzeczywistości jest to czarno-biała wersja obrazu, z którą możesz już pracować. Odcień jest reprezentowany jako kąt i odpowiada za główny ton. Nasycenie koloru zależy od wartości Nasycenie (odległość od środka do krawędzi).

HSV jest znacznie bliżej tego, jak myślimy o kolorach. Jeśli pokażesz czerwony i zielony przedmiot osobie w ciemności, nie będzie ona w stanie rozróżnić kolorów. To samo dzieje się w HSV. Im dalej w dół osi V, tym mniejsza staje się różnica pomiędzy odcieniami, gdyż zmniejsza się zakres wartości nasycenia. Na schemacie wygląda jak stożek, nad którym znajduje się niezwykle czarna kropka.
Kolor i światło
Dlaczego ważne jest posiadanie danych o ilości światła? W większości przypadków w wizji komputerowej kolor nie ma znaczenia, ponieważ nie przenosi żadnych ważna informacja. Przyjrzyjmy się dwóm zdjęciom: kolorowym i czarno-białym. Rozpoznanie wszystkich obiektów w wersji czarno-białej nie jest dużo trudniejsze niż w wersji kolorowej. W tym przypadku kolor nie jest dla nas dodatkowym obciążeniem i powstaje bardzo dużo problemów obliczeniowych. Kiedy pracujemy z kolorową wersją obrazu, ilość danych jest z grubsza podzielona na kostki.
Kolor jest używany tylko w rzadkich przypadkach, gdy przeciwnie, pozwala uprościć obliczenia. Na przykład, gdy musisz wykryć twarz: łatwiej jest najpierw znaleźć jej możliwą lokalizację na zdjęciu, skupiając się na zakresie odcieni skóry. Eliminuje to konieczność analizy całego obrazu.
Funkcje lokalne i globalne
Cechy, według których analizujemy wizerunek, mają charakter lokalny i globalny. Patrząc na to zdjęcie, większość powie, że przedstawia czerwony samochód:
Taka odpowiedź implikuje, że dana osoba zidentyfikowała obiekt na obrazie, co oznacza, że opisał lokalną cechę koloru. Ogólnie rzecz biorąc, obraz przedstawia las, drogę i mały samochód. Pod względem powierzchni samochód zajmuje mniejszą część. Ale rozumiemy, że samochód na tym zdjęciu to najważniejszy obiekt. Jeśli komuś zaproponuje się znalezienie zdjęć podobnych do tego, najpierw wybierze zdjęcia, na których znajduje się czerwony samochód.
Wykrywanie i segmentacja
W wizji komputerowej proces ten nazywa się wykrywaniem i segmentacją. Segmentacja to podział obrazu na wiele części, które są ze sobą powiązane wizualnie lub semantycznie. A detekcja to wykrywanie obiektów na obrazie. Wykrywanie należy wyraźnie odróżnić od rozpoznania. Powiedzmy, że znak drogowy można wykryć na tym samym zdjęciu z samochodem. Ale nie można go rozpoznać, ponieważ jest zwrócony do nas. Odwrotna strona. Ponadto, rozpoznając twarze, wykrywacz może określić położenie twarzy, a „rozpoznawanie” już powie, czyja to twarz.
Deskryptory i słowa wizualne
Istnieje wiele różnych podejść do rozpoznawania.Na przykład to: na obrazku musisz najpierw wybrać interesujące punkty lub interesujące miejsca. Coś innego niż tło: jasne punkty, przejścia itp. Jest do tego kilka algorytmów.
Jeden z najczęstszych sposobów nazywa się różnicą gaussów (DoG). Rozmywając obraz różnymi promieniami i porównując wyniki, można znaleźć najbardziej kontrastujące fragmenty. Najciekawsze są tereny wokół tych fragmentów.
Poniższe zdjęcie pokazuje, jak to wygląda. Otrzymane dane są zapisywane w deskryptorach.

Aby te same deskryptory były rozpoznawane jako takie niezależnie od obrotów w płaszczyźnie, są one obracane tak, aby największe wektory były obracane w tym samym kierunku. Nie zawsze tak się dzieje. Ale jeśli chcesz wykryć dwa identyczne obiekty znajdujące się w różnych płaszczyznach.
Deskryptory można zapisać w postaci liczbowej. Uchwyt może być reprezentowany jako punkt w tablicy wielowymiarowej. Na ilustracji mamy dwuwymiarową tablicę. Nasze deskryptory weszły w to. I możemy je zgrupować - podzielić na grupy.

Następnie opisujemy obszar w przestrzeni dla każdego klastra. Kiedy deskryptor wpada w ten obszar, ważne staje się dla nas nie to, czym był, ale który z obszarów, w który się znalazł. A potem możemy porównać obrazy, określając, ile deskryptorów jednego obrazu znalazło się w tych samych klastrach, co deskryptory innego obrazu. Takie skupiska można nazwać słowami wizualnymi.
Aby znaleźć nie tylko identyczne zdjęcia, ale zdjęcia podobnych obiektów, musisz zrobić wiele zdjęć tego obiektu i wiele zdjęć, na których tak nie jest. Następnie wybierz z nich deskryptory i pogrupuj je. Następnie musisz dowiedzieć się, do jakich klastrów wpadły deskryptory z obrazów, które zawierały potrzebny nam obiekt. Teraz wiemy, że jeśli deskryptory z nowego obrazu mieszczą się w tych samych klastrach, oznacza to, że znajduje się na nim pożądany obiekt.
Zbieżność deskryptorów nie jest jeszcze gwarancją tożsamości zawierających je obiektów. Jednym ze sposobów dodatkowej weryfikacji jest walidacja geometryczna. W tym przypadku porównywane jest położenie deskryptorów względem siebie.
Rozpoznawanie i klasyfikacja
Dla uproszczenia wyobraźmy sobie, że możemy podzielić wszystkie obrazy na trzy klasy: architekturę, przyrodę i portret. Z kolei naturę możemy podzielić na rośliny, zwierzęta i ptaki. A skoro już zrozumieliśmy, że to ptak, możemy powiedzieć, który: sowa, mewa czy wrona.
Różnica między rozpoznawaniem a klasyfikacją jest dość względna. Jeśli na zdjęciu znaleźliśmy sowę, to jest to raczej uznanie. Jeśli tylko ptak, to jest to jakaś opcja pośrednia. A gdyby tylko natura była zdecydowanie klasyfikacją. Tych. różnica między rozpoznawaniem a klasyfikacją polega na tym, jak głęboko przeszliśmy przez drzewo. Im dalej posuwa się widzenie komputerowe, tym niższa będzie granica między klasyfikacją a rozpoznawaniem.
Wróćmy do dzieciństwa i pamiętajmy o fantazji. Cóż, przynajmniej Gwiezdne Wojny, gdzie jest taki żółty humanoidalny robot. W jakiś magiczny sposób porusza się i orientuje w kosmosie. W rzeczywistości ten robot ma „oczy” i „widzi” otaczającą przestrzeń. Ale jak komputery mogą cokolwiek zobaczyć? Kiedy patrzymy na coś, rozumiemy to, co widzimy; dla nas informacje wizualne mają znaczenie. Ale podłączając kamery wideo do komputera, otrzymamy tylko zestaw zer i jedynek, które odczyta z tej kamery wideo. Jak komputer może „zrozumieć” to, co „widzi”? Aby odpowiedzieć na to pytanie, powstała taka dyscyplina naukowa jak Computer Vision (Computer Vision). Zasadniczo, Computer Vision to nauka o tym, jak tworzyć algorytmy, które analizują obrazy i szukają przydatna informacja(informacja, że robot musi nawigować zgodnie z danymi pochodzącymi z kamery). Zadanie wizji komputerowej jest w rzeczywistości zadaniem.
Istnieje kilka kierunków i podejść w Computer Vision:
- Wstępne przetwarzanie obrazu.
- Segmentacja.
- Dobór konturów.
- Znajdowanie specjalnych punktów.
- Znajdowanie obiektów na obrazie.
- Rozpoznawanie wzorców.
Przeanalizujmy je bardziej szczegółowo.
Wstępne przetwarzanie obrazu. Z reguły przed analizą obrazu należy przeprowadzić wstępną obróbkę, która ułatwi analizę. Na przykład usuń szum lub niektóre drobne drobne szczegóły, które zakłócają analizę, lub wykonaj inne przetwarzanie, które ułatwi analizę. W szczególności filtr rozmycia obrazu służy do tłumienia szumów i drobnych szczegółów.
Przykład, zaszumiony obraz:
Po zastosowaniu rozmycia gaussowskiego

Ma jednak istotną wadę: wraz z tłumieniem szumów granice między obszarami obrazu zacierają się, a drobne szczegóły nie znikają, po prostu zamieniają się w plamy. Aby wyeliminować te niedociągnięcia, stosuje się filtrowanie medianowe. Świetnie radzi sobie z impulsywnym szumem i usuwaniem drobnych detali, a krawędzie nie są rozmyte. Jednak filtrowanie medianowe nie poradzi sobie z szumem Gaussa.
Segmentacja. Segmentacja to podział obrazu na regiony. Na przykład jeden obszar jest tłem, a drugi konkretnym obiektem. Lub na przykład mamy zdjęcie, gdzie jest plaża morska. Dzielimy go na obszary: morze, plaża, niebo. Do czego służy segmentacja? Otóż mamy na przykład zadanie odnalezienia obiektu na obrazie. Aby przyspieszyć, ograniczamy obszar wyszukiwania do pewnego segmentu, jeśli wiemy na pewno, że obiekt może znajdować się tylko w tym obszarze. Lub np. w geoinformatyce może być zadanie segmentacji zdjęć satelitarnych lub lotniczych.
Przykład. Oto nasz oryginalny obraz:

A oto jego segmentacja:

W tym przypadku do segmentacji wykorzystano cechy tekstury.
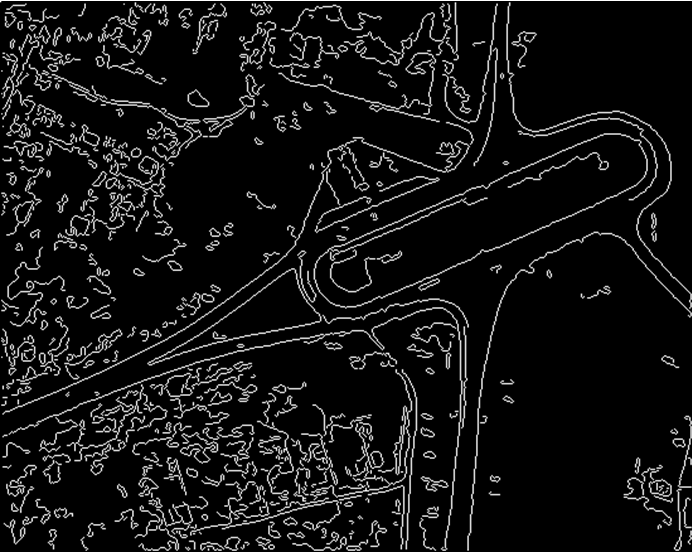
Dobór konturów. Dlaczego na obrazie jest kontur? Załóżmy, że musimy rozwiązać problem odnalezienia twarzy osoby na zdjęciu. Powiedzmy, że najpierw próbowaliśmy rozwiązać ten problem „na czole” – tępe wyliczenie. Bierzemy „kwadrat” z obrazem twarzy i porównujemy go piksel po pikselu z obrazem, przesuwając kwadrat piksel po pikselu od lewej do prawej i tak dalej dla każdego rzędu pikseli. Widać, że będzie to działać zbyt długo, a ponadto taki algorytm nie znajdzie żadnej twarzy, a tylko jedną konkretną. A potem, jeśli trochę go obrócisz lub zmienisz skalę, to wszystko, wyszukiwanie przestanie działać. Inną rzeczą jest to, czy mamy zarys obrazu i zarys twarzy. Linie konturowe możemy opisać w inny sposób niż mapa bitowa, na przykład, jako listę współrzędnych jego punktów, jako grupę prostych opisanych różnymi wzorami matematycznymi. Krótko mówiąc, wybieramy kontur, możemy go wektoryzować i nie szukać już rastra wśród rastra, ale obiektu wektorowego wśród obiektów wektorowych. Jest to znacznie szybsze, a poza tym wtedy opis obiektów może być niezmienny w obrocie i/lub skali (czyli możemy znaleźć obiekty nawet jeśli są obrócone lub przeskalowane).
Teraz pojawia się pytanie: jak wybrać kontur? Z reguły najpierw uzyskuje się tzw. przygotowanie konturu, najczęściej jest to gradient (tempo zmiany jasności). Oznacza to, że po otrzymaniu gradientu obrazu zobaczymy białe obszary, w których występują gwałtowne zmiany jasności, oraz czarne, w których jasność zmienia się płynnie lub wcale. Innymi słowy, wszystkie nasze granice zostaną podkreślone białymi paskami. Ponadto zwężamy te białe paski i uzyskujemy kontur (jeśli krótko opiszemy, co robi algorytm uzyskiwania konturu). Obecnie istnieje szereg standardowych algorytmów wyodrębniania konturów, na przykład algorytm Canny, który jest zaimplementowany w bibliotece OpenCV.
Przykład doboru konturu.
Oryginalny obraz:

Wybrane kontury:
Znajdowanie specjalnych punktów. Inną metodą analizy obrazu jest znajdowanie na nim pojedynczych punktów. Punktami specjalnymi mogą być np. narożniki, ekstrema jasności, a także inne cechy obrazu. Z punktami specjalnymi możesz zrobić to samo, co z konturami - opisz w formie wektorowej. Na przykład możesz opisać względną pozycję punktów za pomocą odległości między punktami. Gdy obiekty są obracane, odległość się nie zmienia, co oznacza, że taki opis będzie niezmienny w stosunku do obrotu. Aby model był również niezmienny w skali, można opisać nie odległość, ale związek między odległościami - rzeczywiście, jeśli odległość jednej pary punktów jest dwa razy większa niż drugiej pary punktów, to zawsze będzie dwa razy większa tak duże, niezależnie od tego, ile razy powiększyliśmy lub pomniejszyliśmy obiekt. Obecnie istnieje wiele typowych algorytmów wyszukiwania punktów osobliwych, na przykład detektor Harris, Moravec, MSER, AKAZE i tak dalej. Wiele istniejących algorytmów znajdowania punktów osobliwych jest zaimplementowanych w OpenCV.
Rozpoznawanie wzorców. Proces ten ma miejsce, gdy obraz jest analizowany, zaznaczane są na nim kontury i konwertowane do postaci wektorowej lub znajdują się punkty osobliwe i obliczane jest ich względne położenie (lub oba razem). Generalnie uzyskano zestaw cech, zgodnie z którymi ustala się, jakie obiekty znajdują się na zdjęciu. W tym celu wykonywane są różne algorytmy heurystyczne, na przykład . Ogólnie rzecz biorąc, jak rozpoznawać obrazy to cała nauka zwana Teoria rozpoznawania wzorców.
Rozpoznawanie wzorców polega na przypisaniu danych początkowych do określonej klasy poprzez wyróżnienie podstawowych cech charakteryzujących te dane z całkowitej masy nieistotnych danych. Przy stawianiu problemów rozpoznawania starają się posługiwać językiem matematycznym, próbując – w przeciwieństwie do teorii sztucznych sieci neuronowych, gdzie podstawą jest uzyskanie wyniku poprzez eksperyment – zastąpić eksperyment logicznym rozumowaniem i dowodami matematycznymi. Klasyczne sformułowanie problemu rozpoznawania wzorców: Dany zbiór obiektów. Muszą być sklasyfikowane. Zbiór jest reprezentowany przez podzbiory, które nazywamy klasami. Podane: informacje o klasach, opis całego zestawu oraz opis informacji o obiekcie, którego przynależność do określonej klasy jest nieznana. Wymagane jest, zgodnie z dostępnymi informacjami o klasach i opisem obiektu, ustalenie do jakiej klasy należy ten obiekt.
Istnieje kilka podejść do rozpoznawania wzorców:
- Wyliczenie. Każda klasa jest określana poprzez bezpośrednie określenie jej członków. To podejście jest stosowane, jeśli dostępna jest pełna informacja a priori o wszystkich możliwych obiektach rozpoznania. Obrazy prezentowane w systemie są porównywane z podanymi opisami przedstawicieli klas i odnoszą się do klasy, do której należą próbki najbardziej do nich zbliżone. Takie podejście nazywa się metodą benchmarkingu. Ma to na przykład zastosowanie przy rozpoznawaniu znaków maszynowych określonej czcionki. Jego wadą jest słaba odporność na szumy i zniekształcenia w rozpoznawalnych obrazach.
- Ustawianie właściwości ogólnych. Klasa jest definiowana przez określenie pewnych cech wspólnych dla wszystkich jej członków. Rozpoznany obiekt w tym przypadku nie jest bezpośrednio porównywany z grupą obiektów referencyjnych. W jego podstawowym opisie wyróżnione są wartości pewnego zestawu cech, które następnie są porównywane z cechami danej klasy. Takie podejście nazywa się dopasowywaniem funkcji. Jest bardziej ekonomiczny niż metoda benchmarkingowa pod względem ilości pamięci wymaganej do przechowywania opisów klas. Ponadto pozwala na pewną zmienność rozpoznawalnych obrazów. Jednak główną trudnością jest określenie pełnego zestawu cech, które dokładnie odróżniają członków jednej klasy od członków wszystkich innych.
- Grupowanie. W przypadku, gdy obiekty opisane są wektorami cech lub pomiarów, klasę można uznać za klaster. Rozpoznanie odbywa się na podstawie obliczenia odległości (najczęściej jest to odległość euklidesowa) opisu obiektu do każdego z dostępnych skupień. Jeżeli skupienia są wystarczająco oddalone od siebie w przestrzeni, metoda rozpoznawania dobrze sprawdza się przy szacowaniu odległości od rozważanego obiektu do każdego z skupisk. Złożoność rozpoznawania wzrasta, jeśli klastry nakładają się na siebie. Jest to zwykle konsekwencją niewystarczających informacji początkowych i można je rozwiązać, zwiększając liczbę pomiarów obiektu. W celu określenia początkowych klastrów wskazane jest skorzystanie z procedury uczenia.
Aby przeprowadzić procedurę rozpoznawania wzorców, trzeba jakoś opisać obiekty. Istnieje również kilka sposobów na opisanie obiektów:
- Przestrzeń euklidesowa— obiekty są reprezentowane przez punkty w przestrzeni euklidesowej ich obliczonych parametrów, reprezentowane jako zbiór pomiarów;
- Listy funkcji- identyfikacja cech jakościowych obiektu i budowa wektora charakteryzującego;
- Opis strukturalny— identyfikacja elementów konstrukcyjnych obiektu i określenie ich relacji.
Znajdowanie obiektów na obrazie. Zadanie odnalezienia obiektów na obrazie sprowadza się do tego, że musimy znaleźć wcześniej znany obiekt, na przykład twarz osoby. Dla tego dany obiekt opisujemy za pomocą pewnych znaków i szukamy na obrazie obiektu, który spełnia te znaki. Zadanie to jest podobne do zadania rozpoznawania wzorców, z tą tylko różnicą, że tutaj nie trzeba klasyfikować nieznanego obiektu, ale znaleźć, gdzie na obrazie znajduje się znany obiekt o określonych cechach. Często zadanie znajdowania obiektów na obrazach podlega wymaganiom wydajnościowym, ponieważ musi to odbywać się w czasie rzeczywistym.
Klasycznym przykładem takich algorytmów jest rozpoznawanie twarzy metodą Viola Johnsona. Chociaż ta metoda została opracowana i wprowadzona w 2001 roku przez Paula Violę i Michaela Jonesa, nadal ma podstawowe znaczenie dla wyszukiwania obiektów obrazu w czasie rzeczywistym. Główne zasady, na których opiera się metoda to:
- Obrazy są używane w reprezentacji integralnej, co pozwala szybko obliczyć niezbędne obiekty;
- Stosuje się znaki haar, za pomocą których przeszukuje się pożądany obiekt (w tym kontekście twarz i jej cechy);
- Boosting służy (od angielskiego boost – ulepszanie, wzmacnianie) do wybrania najbardziej odpowiednich cech dla pożądanego obiektu w danej części obrazu;
- Wszystkie cechy są podawane na wejście klasyfikatora, co daje wynik „prawda” lub „fałsz”;
- Kaskady funkcji służą do szybkiego odrzucania okien, w których nie znaleziono twarzy.
Powiem kilka słów o integralnym obrazie. Faktem jest, że w zadaniach widzenia komputerowego często konieczne jest zastosowanie metody okna skanowania: przesuwamy okno piksel po pikselu po całym obrazie i wykonujemy określony algorytm dla każdego piksela okna. Jak powiedziałem na początku artykułu, takie podejście jest powolne, zwłaszcza jeśli rozmiar przesuwanego okna i obrazu jest duży. Na przykład, jeśli mamy obraz o rozmiarze 1000 na 1000, to będzie to milion pikseli. A jeśli okno przesuwne ma wymiary 10 na 10, to ma 100 pikseli, a algorytm przetwarzający sto pikseli musi zostać wykonany milion razy. Uzyskując obraz całkowity, najeżdżamy na obraz 1 raz i otrzymujemy macierz, w której każdy piksel jest sumą jasności prostokąta ograniczonego przez ten piksel i pochodzenia. Dzięki takiej macierzy możemy obliczyć w zaledwie 4 operacjach możemy obliczyć sumę jasności dowolnego prostokąta (co najmniej 10 na 10, co najmniej 30 na 30, co najmniej 100 na 50). Z reguły w wielu przypadkach przetwarzanie w oknie przesuwnym sprowadza się do obliczenia sumy jasności.
Wizja komputerowa i rozpoznawanie obrazu są integralną częścią (AI), która przez lata zyskała ogromną popularność. W styczniu tego roku odbyły się targi CES 2017, na których można było przyjrzeć się najnowszym osiągnięciom w tej dziedzinie. Tu jest kilka ciekawe przykłady wykorzystanie wizji komputerowej, którą można było zobaczyć na wystawie.
8 przypadków użycia wizji komputerowej
Weronika Elkina1. Samojezdne samochody
Największe stoiska z komputerową wizją należą do branży motoryzacyjnej. W końcu technologie samochodów autonomicznych i półautonomicznych działają w dużej mierze dzięki wizji komputerowej.
Produkty firmy NVIDIA, która poczyniła już wielkie postępy w dziedzinie uczenia głębokiego, znajdują zastosowanie w wielu autonomicznych samochodach. Na przykład superkomputer NVIDIA Drive PX 2 służy już jako podstawowa platforma dla dronów, Volvo, Audi, BMW i Mercedes-Benz.
Technologia sztucznej percepcji DriveNet firmy NVIDIA to samoucząca się wizja komputerowa zasilana przez sieci neuronowe. Z jego pomocą lidary, radary, kamery i czujniki ultradźwiękowe w stanie rozpoznaćśrodowisko, oznakowanie dróg, transport i wiele więcej.
3. Interfejsy
Technologia śledzenia wzroku wykorzystująca widzenie komputerowe znajduje zastosowanie nie tylko w laptopy do gier, ale także w zwykłych i firmowych komputerach, aby mogły nimi sterować osoby, które nie potrafią posługiwać się rękami. Tobii Dynavox PCEye Mini ma rozmiar długopisu i jest idealnym dyskretnym akcesorium do tabletów i laptopów. Ponadto ta technologia śledzenia wzroku jest używana w nowych grach i konwencjonalne laptopy Smartfony Asusa i Huawei.
Tymczasem kontrola gestami (technologia wizyjna komputerowa, która może rozpoznawać określone ruchy rąk) wciąż ewoluuje. Będzie teraz stosowany w przyszłych samochodach BMW i Volkswagen.

Nowy interfejs HoloActive Touch pozwala użytkownikom sterować wirtualnymi ekranami 3D i naciskać przyciski w przestrzeni. Można powiedzieć, że jest prosta wersja prawdziwy holograficzny interfejs Iron Mana (w ten sam sposób reaguje nawet drobną wibracją na naciskane elementy). Dzięki technologiom takim jak ManoMotion łatwo będzie dodać sterowanie gestami do niemal każdego urządzenia. Co więcej, aby uzyskać kontrolę nad wirtualnym obiektem 3D za pomocą gestów, ManoMotion wykorzystuje zwykłą kamerę 2D, więc nie potrzebujesz żadnego dodatkowego sprzętu.
Urządzenie Singlecue Gen 2 firmy eyeSight wykorzystuje widzenie komputerowe (rozpoznawanie gestów, analiza twarzy, wykrywanie akcji) i pozwala sterować telewizorem, inteligentnym systemem oświetlenia i lodówkami za pomocą gestów.

haj
Projekt crowdfundingowy Hayo jest prawdopodobnie najciekawszym nowym interfejsem w historii. Ta technologia umożliwia tworzenie wirtualnych elementów sterujących w całym domu - po prostu podnosząc lub opuszczając rękę, możesz zwiększyć lub zmniejszyć głośność muzyki lub włączyć światło w kuchni, machając ręką nad blatem. Wszystko działa dzięki cylindrycznemu urządzeniu, które wykorzystuje widzenie komputerowe, a także zintegrowanej kamerze oraz czujnikom 3D, podczerwieni i ruchu.
4. Sprzęt AGD
Drogie kamery, które pokazują, co jest w twojej lodówce, nie wydają się już tak rewolucyjne. Ale co z aplikacją, która analizuje obraz z wbudowanej kamery lodówki i informuje, kiedy kończy Ci się określona żywność?

Elegancka FridgeCam firmy Smarter jest montowana z boku lodówki i może powiedzieć, kiedy jest data ważności, dokładnie określić, co jest w lodówce, a nawet polecić przepisy na wybrane produkty spożywcze. Urządzenie sprzedawane jest w nieoczekiwanie przystępnej cenie – zaledwie 100 dolarów.
5. Cyfrowe oznakowanie
Wizja komputerowa może zmienić wygląd banerów i reklam w sklepach, muzeach, stadionach i parkach rozrywki.
Na stoisku Panasonic zaprezentowano wersję demonstracyjną technologii wyświetlania obrazów na flagach. Za pomocą niewidocznych dla ludzkiego oka znaczników podczerwieni i stabilizacji obrazu, technologia ta może wyświetlać reklamy na wiszących banerach, a nawet flagach łopoczących na wietrze. Co więcej, obraz będzie wyglądał tak, jakby był naprawdę na nich wydrukowany.
6. Smartfony i rozszerzona rzeczywistość
Wiele osób mówiło o grze jako o pierwszej masowej aplikacji z elementami (AR). Jednak, podobnie jak inne aplikacje, które próbują wskoczyć do pociągu AR, ta gra w większym stopniu wykorzystywała GPS i triangulację, aby dać użytkownikom wrażenie, że obiekt znajduje się tuż przed nimi. Smartfony zazwyczaj w ogóle nie korzystają z prawdziwych technologii widzenia komputerowego.

Jednak w listopadzie Lenovo wypuściło Phab2, pierwszy smartfon obsługujący technologię Google Tango. Ta technologia to połączenie czujników i oprogramowania komputerowego, które może rozpoznawać obrazy, filmy i świat w czasie rzeczywistym za pomocą obiektywu aparatu.

Na targach CES Asus po raz pierwszy zaprezentował ZenPhone AR, smartfon Google z obsługą Tango i Daydream VR. Smartfon nie tylko potrafi śledzić ruchy, analizować otoczenie i dokładnie określać pozycję, ale także wykorzystuje procesor Qualcomm Snapdragon 821, który pozwala na rozłożenie obciążenia danymi wizji komputerowej. Wszystko to pomaga zastosować prawdziwe technologie rozszerzonej rzeczywistości, które faktycznie analizują sytuację za pomocą kamery smartfona.
Jeszcze w tym roku pojawi się Changhong H2, pierwszy smartfon z wbudowanym skanerem molekularnym. Zbiera światło odbite od obiektu i rozkłada je na widmo, a następnie je analizuje skład chemiczny. Dzięki oprogramowanie za pomocą wizji komputerowej uzyskane informacje można wykorzystać do różnych celów - od przepisywania leków i liczenia kalorii po określanie stanu skóry i obliczanie poziomu otłuszczenia.
| Konferencja Big Data odbędzie się 15 września w Moskwie Konferencja Big Data. W programie znajdują się business case, rozwiązania techniczne oraz osiągnięcia naukowe najlepszych specjalistów w tej dziedzinie. Zapraszamy wszystkich, którzy są zainteresowani pracą z big data i chcą ją zastosować w prawdziwym biznesie. Śledź konferencję Big Data na |
Zakres wizji komputerowej jest bardzo szeroki: od czytników kodów kreskowych w supermarketach po rozszerzoną rzeczywistość. Na tym wykładzie dowiesz się, gdzie i jak działa wizja komputerowa, jak wyglądają obrazy cyfrowe, jakie zadania w tym obszarze są stosunkowo łatwe do rozwiązania, a które trudne i dlaczego.
Wykład przeznaczony jest dla uczniów szkół ponadgimnazjalnych - uczniów Małego SHAD, ale dorośli mogą się z niego nauczyć także wielu przydatnych rzeczy.
Zdolność widzenia i rozpoznawania przedmiotów jest dla człowieka naturalną i nawykową możliwością. Jednak dla komputera do tej pory – jest to niezwykle trudne zadanie. Obecnie podejmowane są próby nauczenia komputera przynajmniej ułamka tego, czego człowiek używa na co dzień, nawet tego nie zauważając.
Prawdopodobnie najczęściej zwykły człowiek styka się z wizją komputerową przy kasie w supermarkecie. Oczywiście mówimy o odczytywaniu kodów kreskowych. Zostały one specjalnie zaprojektowane w taki sposób, aby proces odczytu był jak najłatwiejszy dla komputera. Ale są też bardziej złożone zadania: odczytywanie numerów samochodów, analiza obrazów medycznych, wykrywanie wad w produkcji, rozpoznawanie twarzy itp. Aktywnie rozwija się wykorzystanie wizji komputerowej do tworzenia systemów rzeczywistości rozszerzonej.
Różnica między widzeniem ludzkim a komputerowym
Dziecko uczy się stopniowo rozpoznawać przedmioty. Zaczyna zdawać sobie sprawę, jak zmienia się kształt przedmiotu w zależności od jego położenia i oświetlenia. W przyszłości, rozpoznając przedmioty, osoba skupia się na wcześniejszych doświadczeniach. Podczas swojego życia człowiek gromadzi ogromną ilość informacji, proces uczenia się sieci neuronowej nie zatrzymuje się ani na sekundę. Nie jest szczególnie trudno przywrócić perspektywę z płaskiego obrazu i wyobrazić sobie, jak to wszystko wygląda w trzech wymiarach.Wszystko to jest znacznie trudniejsze dla komputera. A przede wszystkim z powodu problemu akumulacji doświadczenia. Konieczne jest zebranie ogromnej liczby przykładów, co do tej pory nie jest zbyt udane.
Ponadto, rozpoznając obiekt, osoba zawsze bierze pod uwagę środowisko. Jeśli wyciągniesz obiekt ze znanego otoczenia, rozpoznanie go stanie się zauważalnie trudniejsze. Tutaj również rolę odgrywa doświadczenie nagromadzone przez całe życie, którego komputer nie posiada.
Chłopiec czy dziewczyna?
Wyobraź sobie, że musimy nauczyć się określać płeć osoby (ubranej!) na podstawie zdjęcia na pierwszy rzut oka. Najpierw musisz określić czynniki, które mogą wskazywać na przynależność do konkretnego obiektu. Dodatkowo musisz zebrać zestaw treningowy. Pożądane jest, aby był reprezentatywny. W naszym przypadku jako próbkę szkoleniową weźmiemy wszystkich obecnych na widowni. I spróbujmy na ich podstawie znaleźć wyróżniki: na przykład długość włosów, obecność brody, makijaż i ubiór (spódnica lub spodnie). Wiedząc, jaki procent przedstawicieli tej samej płci spotkał określone czynniki, będziemy w stanie stworzyć dość jasne reguły: obecność tych lub innych kombinacji czynników z pewnym prawdopodobieństwem pozwoli nam powiedzieć, jakiej płci jest dana osoba na zdjęciu.Nauczanie maszynowe
Oczywiście jest to bardzo prosty i warunkowy przykład z niewielką liczbą czynników wysokiego poziomu. W rzeczywistych zadaniach stawianych przed komputerowymi systemami wizyjnymi jest o wiele więcej czynników. Określanie ich ręcznie i obliczanie zależności jest dla człowieka zadaniem niewykonalnym. Dlatego w takich przypadkach uczenie maszynowe jest niezbędne. Na przykład można zdefiniować kilkadziesiąt czynników początkowych, a także podać przykłady pozytywne i negatywne. I już zależności między tymi czynnikami są wybierane automatycznie, powstaje formuła, która pozwala podejmować decyzje. Dość często same czynniki są przydzielane automatycznie.Obraz w liczbach
Najczęściej używaną przestrzenią kolorów dla obrazów cyfrowych jest RGB. W nim każdej z trzech osi (kanałów) przypisany jest własny kolor: czerwony, zielony i niebieski. Każdemu kanałowi przydzielone jest odpowiednio 8 bitów informacji, intensywność kolorów na każdej osi może przyjmować wartości z zakresu od 0 do 255. Wszystkie kolory w przestrzeni cyfrowej RGB uzyskuje się poprzez zmieszanie trzech kolorów podstawowych.Niestety, RGB nie zawsze dobrze nadaje się do analizy informacji. Eksperymenty pokazują, że geometryczna bliskość kolorów jest dość daleka od tego, jak osoba postrzega bliskość niektórych kolorów do siebie.
Ale są też inne przestrzenie kolorów. Przestrzeń HSV (Hue, Saturation, Value) jest bardzo interesująca w naszym kontekście. Posiada oś Wartość wskazującą ilość światła. Przydzielony jest do niego osobny kanał, w przeciwieństwie do RGB, gdzie ta wartość musi być każdorazowo obliczana. W rzeczywistości jest to czarno-biała wersja obrazu, z którą możesz już pracować. Odcień jest reprezentowany jako kąt i odpowiada za główny ton. Nasycenie koloru zależy od wartości Nasycenie (odległość od środka do krawędzi).
HSV jest znacznie bliżej tego, jak myślimy o kolorach. Jeśli pokażesz czerwony i zielony przedmiot osobie w ciemności, nie będzie ona w stanie rozróżnić kolorów. To samo dzieje się w HSV. Im dalej w dół osi V, tym mniejsza staje się różnica pomiędzy odcieniami, gdyż zmniejsza się zakres wartości nasycenia. Na schemacie wygląda jak stożek, nad którym znajduje się niezwykle czarna kropka.
Kolor i światło
Dlaczego ważne jest posiadanie danych o ilości światła? W większości przypadków w wizji komputerowej kolor nie ma znaczenia, ponieważ nie zawiera żadnych ważnych informacji. Przyjrzyjmy się dwóm zdjęciom: kolorowym i czarno-białym. Rozpoznanie wszystkich obiektów w wersji czarno-białej nie jest dużo trudniejsze niż w wersji kolorowej. W tym przypadku kolor nie jest dla nas dodatkowym obciążeniem i powstaje bardzo dużo problemów obliczeniowych. Kiedy pracujemy z kolorową wersją obrazu, ilość danych jest z grubsza podzielona na kostki.
Kolor jest używany tylko w rzadkich przypadkach, gdy przeciwnie, pozwala uprościć obliczenia. Na przykład, gdy musisz wykryć twarz: łatwiej jest najpierw znaleźć jej możliwą lokalizację na zdjęciu, skupiając się na zakresie odcieni skóry. Eliminuje to konieczność analizy całego obrazu.
Funkcje lokalne i globalne
Cechy, według których analizujemy wizerunek, mają charakter lokalny i globalny. Patrząc na to zdjęcie, większość powie, że przedstawia czerwony samochód:
Taka odpowiedź implikuje, że dana osoba zidentyfikowała obiekt na obrazie, co oznacza, że opisał lokalną cechę koloru. Ogólnie rzecz biorąc, obraz przedstawia las, drogę i mały samochód. Pod względem powierzchni samochód zajmuje mniejszą część. Ale rozumiemy, że samochód na tym zdjęciu to najważniejszy obiekt. Jeśli komuś zaproponuje się znalezienie zdjęć podobnych do tego, najpierw wybierze zdjęcia, na których znajduje się czerwony samochód.
Wykrywanie i segmentacja
W wizji komputerowej proces ten nazywa się wykrywaniem i segmentacją. Segmentacja to podział obrazu na wiele części, które są ze sobą powiązane wizualnie lub semantycznie. A detekcja to wykrywanie obiektów na obrazie. Wykrywanie należy wyraźnie odróżnić od rozpoznania. Powiedzmy, że znak drogowy można wykryć na tym samym zdjęciu z samochodem. Ale nie można go rozpoznać, ponieważ jest do nas zwrócony. Ponadto, rozpoznając twarze, wykrywacz może określić położenie twarzy, a „rozpoznawanie” już powie, czyja to twarz.
Deskryptory i słowa wizualne
Istnieje wiele różnych podejść do rozpoznawania.Na przykład to: na obrazie musisz najpierw podświetlić interesujące punkty lub ciekawe miejsca. Coś innego niż tło: jasne punkty, przejścia itp. Jest do tego kilka algorytmów.
Jeden z najczęstszych sposobów nazywa się różnicą gaussów (DoG). Rozmywając obraz różnymi promieniami i porównując wyniki, można znaleźć najbardziej kontrastujące fragmenty. Najciekawsze są tereny wokół tych fragmentów.
Poniższe zdjęcie pokazuje, jak to wygląda. Otrzymane dane są zapisywane w deskryptorach.
Aby te same deskryptory były rozpoznawane jako takie niezależnie od obrotów w płaszczyźnie, są one obracane tak, aby największe wektory były obracane w tym samym kierunku. Nie zawsze tak się dzieje. Ale jeśli chcesz wykryć dwa identyczne obiekty znajdujące się w różnych płaszczyznach.
Deskryptory można zapisać w postaci liczbowej. Uchwyt może być reprezentowany jako punkt w tablicy wielowymiarowej. Na ilustracji mamy dwuwymiarową tablicę. Nasze deskryptory weszły w to. I możemy je zgrupować - podzielić na grupy.
Następnie opisujemy obszar w przestrzeni dla każdego klastra. Kiedy deskryptor wpada w ten obszar, ważne staje się dla nas nie to, czym był, ale który z obszarów, w który się znalazł. A potem możemy porównać obrazy, określając, ile deskryptorów jednego obrazu znalazło się w tych samych klastrach, co deskryptory innego obrazu. Takie skupiska można nazwać słowami wizualnymi.
Aby znaleźć nie tylko identyczne zdjęcia, ale zdjęcia podobnych obiektów, musisz zrobić wiele zdjęć tego obiektu i wiele zdjęć, na których tak nie jest. Następnie wybierz z nich deskryptory i pogrupuj je. Następnie musisz dowiedzieć się, do jakich klastrów wpadły deskryptory z obrazów, które zawierały potrzebny nam obiekt. Teraz wiemy, że jeśli deskryptory z nowego obrazu mieszczą się w tych samych klastrach, oznacza to, że znajduje się na nim pożądany obiekt.
Zbieżność deskryptorów nie jest jeszcze gwarancją tożsamości zawierających je obiektów. Jednym ze sposobów dodatkowej weryfikacji jest walidacja geometryczna. W tym przypadku porównywane jest położenie deskryptorów względem siebie.
Rozpoznawanie i klasyfikacja
Dla uproszczenia wyobraźmy sobie, że możemy podzielić wszystkie obrazy na trzy klasy: architekturę, przyrodę i portret. Z kolei naturę możemy podzielić na rośliny, zwierzęta i ptaki. A skoro już zrozumieliśmy, że to ptak, możemy powiedzieć, który: sowa, mewa czy wrona.
Różnica między rozpoznawaniem a klasyfikacją jest dość względna. Jeśli na zdjęciu znaleźliśmy sowę, to jest to raczej uznanie. Jeśli tylko ptak, to jest to jakaś opcja pośrednia. A gdyby tylko natura była zdecydowanie klasyfikacją. Tych. różnica między rozpoznawaniem a klasyfikacją polega na tym, jak głęboko przeszliśmy przez drzewo. Im dalej posuwa się widzenie komputerowe, tym niższa będzie granica między klasyfikacją a rozpoznawaniem.