Mamy: php 5.2.3, Windows XP, Apache 1.3.33
Problem - moduł cURL nie jest wykrywany, jeśli PHP jest uruchamiane z Apache
W php.ini extension=php_curl.dll jest odkomentowany, extension_dir jest ustawione poprawnie,
libeay32.dll i ssleay32.dll są kopiowane do c:\windows\system32.
Jednak funkcja phpinfo() nie pokazuje modułu cURL wśród zainstalowanych, a po uruchomieniu Apache do dziennika zapisywane jest:
Uruchomienie PHP: Nie można załadować biblioteki dynamicznej "c:/php/ext/php_curl.dll" — Nie można znaleźć określonego modułu.
Jeśli uruchamiasz php z wiersz poleceń, to skrypty zawierające polecenia z cURL działają dobrze, a uruchomione z Apache dają:
Błąd krytyczny: Wywołanie niezdefiniowanej funkcji: curl_init() — niezależnie od tego, jak PHP jest zainstalowane — jako CGI lub jako moduł.
W internecie wielokrotnie natknąłem się na opis tego problemu – konkretnie dla modułu cURL, ale rozwiązania, które tam zaproponowano, nie pomagają. Zmieniłem już PHP 5.2 na PHP 5.2.3 - nadal nie pomogło.
Dawid Mzareulyan[dossier]
Mam jeden php.ini - sprawdziłem go przeszukując dysk. O tym, że używany jest ten sam php.ini, świadczy też fakt, że wprowadzone w nim zmiany wpływają zarówno na uruchamianie skryptów spod Apache'a, jak iz linii poleceń.
Daniił Iwanow[dossier] Lepiej utwórz plik za pomocą połączenia
i otwórz go w przeglądarce.
A potem uruchom php -i | grep ini i sprawdź ścieżki do php.ini tak, jak widzi je php, a nie przez obecność pliku na dysku.
Daniił Iwanow[dossier] Co wyświetla php -i? Domyślny plik binarny może szukać konfiguracji gdzie indziej, w zależności od opcji kompilacji. Nie pierwszy raz spotykam się z tym, że mod_php.dll i php.exe przeglądają różne pliki ini i to, co działa w jednym, nie działa w drugim.
Wasilij Sviridov[dossier]
php -i daje następujące:
Ścieżka pliku konfiguracyjnego (php.ini) => C:\WINDOWS
Załadowany plik konfiguracyjny => C:\PHP\php.ini
Przeniesienie pliku php.ini do katalogu Windows nie zmienia sytuacji.
Daniił Iwanow[dossier]
A co z resztą modułów? Na przykład php_mysql??? Złączony? A może to po prostu cURL, który jest taki paskudny?
Hmm, dla mnie też się nie ładuje... Na zupełnie innej konfiguracji (Apache 2.2 plus PHP 5.1.6 pod Zend Studio). Ale nie o to chodzi. Eksperyment z uruchomieniem Apache z linii poleceń (a dokładniej z FAR) pokazał coś ciekawego. Bez próby łączenia Kurla - wszystko zaczyna się w pęczku. Przy próbie połączenia Kurl daje błąd w... php5ts.dll.
Cześć!
Miałam podobny problem długo szukałam rozwiązania, wstawiałam więcej Nowa wersja PHP, w końcu znalazłem to forum. Tutaj nie było rozwiązania, więc sam spróbowałem dalej.
Założyłem dla siebie studio zend, a wcześniej stałem więcej wczesna wersja RNR. Być może któryś z nich zainstalował swoje biblioteki i tam pozostały - przestarzałe.
Dzięki za wskazówki, zwłaszcza ostatnią z "Nehxby". Wszedłem do C:\windows\system32 i stwierdziłem, że biblioteki libeay32.dll i ssleay32.dll nie są tego samego rozmiaru co oryginalne. Zainstalowałem memcached, może po tym. Więc jeśli dodałeś chot, w system32 idź :)
miał ten sam problem, użył polecenia php -i | grep ini
pokazał, że brakuje biblioteki zlib1.dll
to było w folderze z Apache, napisałem kopię w folderze z PHP
Powtórzyłem polecenie, okazało się, że biblioteka zlib.dll nie wystarczy, napisałem w folderze Apache i wszystko działało.
a wszystkie biblioteki były również php5ts.dll, więc rozważ obecność wszystkich niezbędnych bibliotek.
Postanowiłem dodać. Bo ja też spotkałem się z tym problemem. Natknąłem się na to forum poprzez link na innej stronie. Ogólnie wszystkie proponowane opcje to nic innego jak kule. istota rozwiązania w systemie Windows. musisz ustawić zmienną PATH. określając, gdzie masz PHP. a Hallelujah curl nie wyrzuca żadnych błędów. jak inne biblioteki...
cURL to Specjalne narzędzie, który służy do przesyłania plików i danych przy użyciu składni adresu URL. Ta technologia obsługuje wiele protokołów, takich jak HTTP, FTP, TELNET i wiele innych. cURL został pierwotnie zaprojektowany jako narzędzie wiersza poleceń. Na szczęście dla nas biblioteka cURL jest obsługiwana przez język programowanie PHP. W tym artykule przyjrzymy się niektórym zaawansowanym funkcjom cURL, a także dotkniemy praktycznego zastosowania zdobytej wiedzy za pomocą PHP.
Dlaczego CURL?
W rzeczywistości jest ich wiele alternatywne sposoby pobieranie zawartości strony internetowej. W wielu przypadkach, głównie z lenistwa, używałem prosty PHP funkcje zamiast cURL:
$content = file_get_contents("http://www.nettuts.com"); // lub $lines = file("http://www.nettuts.com"); // lub readfile("http://www.nettuts.com");
Jednak funkcje te praktycznie nie są elastyczne i zawierają ogromną liczbę niedociągnięć w zakresie obsługi błędów i tak dalej. Ponadto są pewne zadania, których po prostu nie można rozwiązać za pomocą tych standardowych funkcji: interakcja z plikami cookie, uwierzytelnianie, przesyłanie formularza, przesyłanie plików i tak dalej.
cURL to potężna biblioteka, która obsługuje wiele różnych protokołów, opcji i zapewnia dokładna informacja o żądaniach adresów URL.
Podstawowa struktura
- Inicjalizacja
- Przypisywanie parametrów
- Wykonanie i pobieranie wyniku
- Zwalnianie pamięci
// 1. inicjalizacja $ch = curl_init(); // 2. określ opcje, w tym url curl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. pobierz HTML jako wynik $output = curl_exec($ch); // 4. zamknij połączenie curl_close($ch);
Krok 2 (czyli wywołanie curl_setopt()) zostanie omówiony w tym artykule znacznie częściej niż wszystkie inne kroki, ponieważ. na tym etapie dzieją się wszystkie najciekawsze i najbardziej przydatne rzeczy, o których musisz wiedzieć. Istnieje ogromna liczba różnych opcji w cURL, które należy określić, aby móc skonfigurować żądanie adresu URL w najbardziej dokładny sposób. Nie będziemy rozważać całej listy jako całości, ale skupimy się tylko na tym, co uważam za konieczne i przydatne w tej lekcji. Wszystko inne, co możesz odkryć samodzielnie, jeśli ten temat Cię interesuje.
Sprawdzanie błędów
Dodatkowo możesz również użyć Instrukcje warunkowe aby sprawdzić, czy operacja się powiodła:
// ... $output = curl_exec($ch); if ($output === FALSE) ( echo "cURL Error: " . curl_error($ch); ) // ...
Tutaj proszę bardzo o uwagę ważny punkt: powinniśmy użyć "=== false" do porównania, zamiast "== false". Tym, którzy nie wiedzą, pomoże nam to odróżnić pusty wynik od fałszywej wartości logicznej, która wskaże błąd.
Otrzymywanie informacji
Kolejnym dodatkowym krokiem jest pobranie danych o żądaniu cURL po jego wykonaniu.
// ... curl_exec($ch); $informacja = curl_getinfo($ch); echo "wziął" . $info["całkowity_czas"] . "sekundy na adres URL". $info["url"]; //...
Zwrócona tablica zawiera następujące informacje:
- „adres URL”
- "Typ zawartości"
- http_kod
- „rozmiar_nagłówka”
- "rozmiar_żądania"
- „czas pliku”
- „ssl_verify_result”
- „liczba_przekierowań”
- "czas całkowity"
- „czas_wyszukiwania_nazwa”
- „czas_połączenia”
- "czas_przedtransferu"
- "rozmiar_przesyłania"
- size_download
- „speed_download”
- „prędkość_przesyłania”
- „długość_pobierania_treści”
- „przesyłana_treść_długość”
- "starttransfer_time"
- „czas_przekierowania”
Wykrywanie przekierowań w zależności od przeglądarki
W tym pierwszym przykładzie napiszemy kod, który może wykrywać przekierowania adresów URL na podstawie różne ustawienia przeglądarka. Na przykład niektóre witryny przekierowują przeglądarki komórka lub dowolne inne urządzenie.
Użyjemy opcji CURLOPT_HTTPHEADER, aby określić wychodzące nagłówki HTTP, w tym nazwę przeglądarki użytkownika i dostępne języki. W końcu będziemy mogli określić, które witryny przekierowują nas do różnych adresów URL.
// testowy adres URL $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com"); // testowanie przeglądarek $browsers = array("standard" => array ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5 .6 (.NET CLR 3.5.30729)", "język" => "pl-pl,pl;q=0.5"), "iphone" => tablica ("user_agent" => "Mozilla/5.0 (iPhone; U ; Procesor jak Mac OS X; en) AppleWebKit/420+ (KHTML, jak Gecko) Wersja/3.0 Mobile/1A537a Safari/419.3", "language" => "en"), "french" => array ("user_agent" => "Mozilla/4.0 (zgodna; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "język" => "fr, fr-FR; q=0.5")); foreach ($urls as $url) ( echo "URL: $url\n"; foreach ($browsers as $test_name => $browser) ( $ch = curl_init(); // określ adres URL curl_setopt($ch, CURLOPT_URL, $url); // ustaw nagłówki przeglądarki curl_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: ($browser["user_agent"])", "Accept-Language: ($browser["język"])" ) // nie potrzebujemy zawartości strony curl_setopt($ch, CURLOPT_NOBODY, 1); // potrzebujemy pobrać nagłówki HTTP curl_setopt($ch, CURLOPT_HEADER, 1); // zwraca wyniki zamiast danych wyjściowych curl_setopt($ch , CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($ch); curl_close($ch); // Czy było przekierowanie HTTP? if (preg_match("!Location: (.*)!", $output, $matches) ) ( echo " $nazwa_testu: przekierowuje do $dopasowań\n"; ) else ( echo "$nazwa_testu: brak przekierowań\n"; ) ) echo "\n\n"; )
Najpierw podajemy listę adresów URL witryn, które będziemy sprawdzać. Dokładniej, potrzebujemy adresów tych stron. Następnie musimy zdefiniować ustawienia przeglądarki, aby przetestować każdy z tych adresów URL. Następnie użyjemy pętli, w której prześledzimy wszystkie uzyskane wyniki.
Sztuczka, której używamy w tym przykładzie, aby ustawić ustawienia cURL, pozwoli nam uzyskać nie zawartość strony, ale tylko nagłówki HTTP (przechowywane w $output). Następnie, używając prostego wyrażenia regularnego, możemy określić, czy ciąg „Location:” był obecny w odebranych nagłówkach.
Po uruchomieniu tego kodu powinieneś otrzymać coś takiego:
Wysyłanie żądania POST do określonego adresu URL
Podczas tworzenia żądania GET przesyłane dane mogą zostać przekazane do adresu URL za pomocą „ciągu zapytania”. Na przykład podczas wyszukiwania w Google wyszukiwane hasła znajdują się w pasek adresu nowy adres URL:
http://www.google.com/search?q=ruseller
Aby naśladować dana prośba, nie musisz używać cURL. Jeśli w końcu pokona Cię lenistwo, użyj funkcji „file_get_contents ()”, aby uzyskać wynik.
Ale chodzi o to, że niektóre formularze HTML wysyłają żądania POST. Transport danych tych formularzy odbywa się poprzez treść zapytania HTTP, a nie jak w poprzednim przypadku. Na przykład, jeśli wypełniłeś formularz na forum i kliknąłeś przycisk wyszukiwania, najprawdopodobniej zostanie wysłane żądanie POST:
http://codeigniter.com/forums/do_search/
Możemy pisać Skrypt PHP, który może naśladować tego rodzaju adres URL żądania. Najpierw utwórzmy prosty plik do akceptowania i wyświetlania danych POST. Nazwijmy to post_output.php:
Print_r($_POST);
Następnie tworzymy skrypt PHP do wykonania żądania cURL:
$url = "http://localhost/post_output.php"; $post_data = array("foo" => "bar", "query" => "Nettuts", "action" => "Prześlij"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // wskazuje, że mamy żądanie POST curl_setopt($ch, CURLOPT_POST, 1); // dodaj zmienne curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $wyjście = curl_exec($ch); curl_close($ch); echo $wyjście;
Po uruchomieniu tego skryptu powinieneś otrzymać podobny wynik:

W ten sposób żądanie POST zostało wysłane do skryptu post_output.php, który z kolei wygenerował tablicę superglobalną $_POST, której zawartość uzyskaliśmy za pomocą cURL.
Udostępnianie pliku
Najpierw utwórzmy plik, aby go uformować i wyślij do pliku upload_output.php:
Print_r($_FILES);
A oto kod skryptu, który wykonuje powyższą funkcjonalność:
$url = "http://localhost/upload_output.php"; $post_data = array ("foo" => "bar", // plik do przesłania "upload" => "@C:/wamp/www/test.zip"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $wyjście = curl_exec($ch); curl_close($ch); echo $wyjście;
Gdy chcesz przesłać plik, wystarczy, że przekażesz go jako zwykłą zmienną post, poprzedzoną symbolem @. Po uruchomieniu napisanego skryptu otrzymasz następujący wynik:

Wiele cURL
Jedną z największych zalet cURL jest możliwość tworzenia „wielu” obsługi cURL. Pozwala to na otwarcie połączenia z wieloma adresami URL jednocześnie i asynchronicznie.
W klasycznej wersji żądania cURL wykonanie skryptu jest zawieszone, a operacja żądania adresu URL ma się zakończyć, po czym skrypt może być kontynuowany. Jeśli zamierzasz wchodzić w interakcję z wieloma adresami URL, będzie to dość czasochłonne, ponieważ w klasycznym przypadku możesz pracować tylko z jednym adresem URL na raz. Możemy jednak naprawić tę sytuację za pomocą specjalnych programów obsługi.
Rzućmy okiem na przykład kodu, który wziąłem z php.net:
// utwórz trochę zasobów cURL $ch1 = curl_init(); $ch2 = curl_init(); // określ adres URL i inne parametry curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); curl_setopt($ch1, CURLOPT_HEADER, 0); curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/"); curl_setopt($ch2, CURLOPT_HEADER, 0); //utwórz obsługę wielu cURL $mh = curl_multi_init(); //dodawanie wielu modułów obsługi curl_multi_add_handle($mh,$ch1); curl_multi_add_handle($mh,$ch2); $aktywny = null; //wykonanie wykonaj ( $mrc = curl_multi_exec($mh, $active); ) while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active && $mrc == CURLM_OK) ( if (curl_multi_select($mh) != -1) ( do ( $mrc = curl_multi_exec($mh, $active); ) while ($mrc == CURLM_CALL_MULTI_PERFORM); ) ) //zamknij curl_multi_remove_handle($mh, $ch1); curl_multi_remove_handle($mh, $ch2); curl_multi_close($mh);
Pomysł polega na tym, że możesz używać wielu programów obsługi cURL. Za pomocą prostej pętli możesz śledzić, które żądania nie zostały jeszcze zrealizowane.
W tym przykładzie są dwie główne pętle. Pierwsza pętla do-while wywołuje funkcję curl_multi_exec(). Ta funkcja nie blokuje. Wykonuje się tak szybko, jak to możliwe i zwraca stan żądania. Podczas gdy zwracana wartość to stała 'CURLM_CALL_MULTI_PERFORM', oznacza to, że praca nie została jeszcze zakończona (np. aktualnie wysyłane są nagłówki http w adresie URL); Dlatego sprawdzamy tę zwracaną wartość, aż otrzymamy inny wynik.
W następnej pętli sprawdzamy warunek, podczas gdy $active = "true". Jest to drugi parametr funkcji curl_multi_exec(). Wartość tej zmiennej będzie „prawdziwa”, dopóki którakolwiek z istniejących zmian będzie aktywna. Następnie wywołujemy funkcję curl_multi_select(). Jego wykonanie „blokuje się”, dopóki istnieje co najmniej jedno aktywne połączenie, aż do otrzymania odpowiedzi. Gdy tak się stanie, wracamy do głównej pętli, aby kontynuować wykonywanie żądań.
Teraz zastosujmy to, czego się nauczyliśmy, na przykładzie, który będzie naprawdę przydatny duża liczba ludzi.
Sprawdzanie linków w WordPressie
Wyobraź sobie blog z ogromną liczbą postów i wiadomości, z których każdy zawiera linki do zewnętrznych zasobów internetowych. Niektóre z tych linków mogą być już „martwe” z różnych powodów. Być może strona została usunięta lub witryna w ogóle nie działa.
Stworzymy skrypt, który przeanalizuje wszystkie linki i znajdzie strony, które się nie ładują i strony 404, a następnie dostarczy nam bardzo szczegółowy raport.
Od razu powiem, że nie jest to przykład tworzenia wtyczki do WordPressa. To prawie wszystko, co jest dla nas dobrym poligonem doświadczalnym.
Zacznijmy wreszcie. Najpierw musimy pobrać wszystkie linki z bazy danych:
// konfiguracja $db_host = "localhost"; $db_user = "root"; $db_pass = ""; $db_name = "wordpress"; $excluded_domains = array("host lokalny", "www.mojadomena.com"); $max_połączenia = 10; // inicjalizacja zmiennej $url_list = array(); $working_urls = tablica(); $martwe_urls = tablica(); $not_found_urls = array(); $aktywny = null; // połącz się z MySQL if (!mysql_connect($db_host, $db_user, $db_pass)) ( die("Nie można połączyć: " . mysql_error()); ) if (!mysql_select_db($db_name)) ( die("Można not select db: " . mysql_error()); ) // zaznacz wszystkie opublikowane posty z linkami $q = "SELECT post_content FROM wp_posts WHERE post_content LIKE "%href=%" AND post_status = "publish" AND post_type = "post "" ; $r = mysql_query($q) lub die(mysql_error()); while ($d = mysql_fetch_assoc($r)) ( // pobierz linki za pomocą wyrażeń regularnych if (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $ pasuje) ) ( foreach ($pasuje do $url) ( $tmp = parse_url($url); if (in_array($tmp["host"], $excluded_domains)) ( Continue; ) $url_list = $url; ) ) ) / / usuń duplikaty $url_list = array_values(array_unique($url_list)); if (!$url_list) ( die("Brak adresu URL do sprawdzenia"); )
Najpierw generujemy dane konfiguracyjne do interakcji z bazą danych, następnie piszemy listę domen, które nie będą brały udziału w sprawdzeniu ($excluded_domains). Definiujemy również liczbę, która charakteryzuje liczbę maksymalnych jednoczesnych połączeń, których użyjemy w naszym skrypcie ($max_connections). Następnie dołączamy do bazy danych, wybieramy posty zawierające linki i gromadzimy je w tablicy ($url_list).
Poniższy kod jest nieco skomplikowany, więc zrozum go od początku do końca:
// 1. wielokrotna obsługa $mh = curl_multi_init(); // 2. dodaj dużo adresów URL dla ($i = 0; $i< $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте данный вызов curl_close($mhinfo["handle"]); // 13. добавляем новый url и продолжаем работу if (add_url_to_multi_handle($mh, $url_list)) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } } } // 14. завершение curl_multi_close($mh); echo "==Dead URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==Working URLs==\n"; echo implode("\n",$working_urls); function add_url_to_multi_handle($mh, $url_list) { static $index = 0; // если у нас есть ещё url, которые нужно достать if ($url_list[$index]) { // новый curl обработчик $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_NOBODY, 1); curl_multi_add_handle($mh, $ch); // переходим на следующий url $index++; return true; } else { // добавление новых URL завершено return false; } }
Tutaj postaram się umieścić wszystko na półkach. Numery na liście odpowiadają numerom w komentarzu.
- 1. Utwórz wielokrotną obsługę;
- 2. Nieco później napiszemy funkcję add_url_to_multi_handle(). Za każdym razem, gdy zostanie wywołany, zostanie przetworzony nowy adres URL. Początkowo dodajemy 10 ($max_connections) adresów URL;
- 3. Aby rozpocząć, musimy uruchomić funkcję curl_multi_exec(). Dopóki zwraca CURLM_CALL_MULTI_PERFORM, nadal mamy trochę pracy do wykonania. Potrzebujemy tego głównie do tworzenia połączeń;
- 4. Następnie pojawia się główna pętla, która będzie wykonywana tak długo, jak mamy co najmniej jedno aktywne połączenie;
- 5. curl_multi_select() zawiesza się czekając na zakończenie wyszukiwania adresu URL;
- 6. Po raz kolejny musimy zmusić cURL do wykonania pewnej pracy, a mianowicie do pobrania zwróconych danych odpowiedzi;
- 7. Informacje są tutaj weryfikowane. W wyniku żądania zostanie zwrócona tablica;
- 8. Zwrócona tablica zawiera procedurę obsługi cURL. To jest to, czego użyjemy do pobrania informacji o konkretnym żądaniu cURL;
- 9. Jeśli link był martwy lub skrypt zabrakło czasu, nie powinniśmy szukać żadnego kodu http;
- 10. Jeżeli link zwrócił nam stronę 404, to kod http będzie zawierał wartość 404;
- 11. W przeciwnym razie mamy przed sobą działające łącze. (Możesz dodać dodatkowe sprawdzenia pod kątem kodu błędu 500 itp.);
- 12. Następnie usuwamy procedurę obsługi cURL, ponieważ już jej nie potrzebujemy;
- 13. Teraz możemy dodać kolejny adres URL i uruchomić wszystko, o czym rozmawialiśmy wcześniej;
- 14. Na tym etapie skrypt kończy swoją pracę. Możemy usunąć wszystko, czego nie potrzebujemy i wygenerować raport;
- 15. Na koniec napiszemy funkcję, która doda URL do handlera. Zmienna statyczna $index będzie zwiększana za każdym razem podana funkcja będzie wezwany.
Użyłem tego skryptu na moim blogu (z kilkoma zepsutymi linkami dodanymi celowo, aby go przetestować) i uzyskałem następujący wynik:

W moim przypadku uruchomienie skryptu przez 40 adresów URL zajęło niecałe 2 sekundy. Wzrost wydajności jest znaczący, gdy mamy do czynienia z jeszcze większą liczbą adresów URL. Jeśli otworzysz dziesięć połączeń jednocześnie, skrypt może działać dziesięć razy szybciej.
Kilka słów o innych przydatnych opcjach cURL
Uwierzytelnianie HTTP
Jeśli adres URL ma uwierzytelnianie HTTP, możesz łatwo użyć następującego skryptu:
$url = "http://www.somesite.com/members/"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // określ nazwę użytkownika i hasło curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // jeśli przekierowanie jest dozwolone curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // następnie zapisz nasze dane w cURL curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1); $wyjście = curl_exec($ch); curl_close($ch);
Przesyłanie FTP
PHP posiada również bibliotekę do pracy z FTP, ale nic nie stoi na przeszkodzie, aby używać tutaj narzędzi cURL:
// otwórz plik $plik = fopen("/ścieżka/do/pliku", "r"); // adres URL powinien zawierać następującą treść $url = "ftp://nazwa użytkownika: [e-mail chroniony]:21/ścieżka/do/nowego/pliku"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_UPLOAD, 1); curl_setopt($ch, CURLOPT_INFILE, $fp); curl_setopt($ch, CURLOPT_INFILESIZE, filesize("/ścieżka/do/pliku")); // określ mod ASCII curl_setopt($ch, CURLOPT_FTPASCII, 1); $output = curl_exec ($ch); curl_close($ch);
Korzystanie z proxy
Możesz wysłać żądanie URL przez serwer proxy:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // podaj adres curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // jeśli musisz podać nazwę użytkownika i hasło curl_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $wyjście = curl_exec($ch); curl_close($ch);
Oddzwonienia
Możliwe jest również określenie funkcji, która zostanie uruchomiona przed zakończeniem cURL działa prośba. Na przykład podczas wczytywania treści odpowiedzi możesz zacząć korzystać z danych, nie czekając na ich pełne załadowanie.
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); curl_setopt($ch, CURLOPT_WRITEFUNCTION,"funkcja_postępu"); curl_exec($ch); curl_close($ch); function progress_function($ch,$str) ( echo $str; return strlen($str); )
Taka funkcja MUSI zwracać długość łańcucha, co jest wymagane.
Wniosek
Dzisiaj zapoznaliśmy się z tym, jak można wykorzystać bibliotekę cURL do własnych, egoistycznych celów. Mam nadzieję, że podobał Ci się ten artykuł.
Dzięki! Miłego dnia!
Ci, którzy używają cURL po aktualizacji do 5.6.1, 5.5.17, napotkali fakt, że moduł cURL przestał działać. Od tego czasu problem nie zniknął. Nawet w najnowszej wersji PHP 5.6.4 problem ten utrzymywał się.
Skąd wiesz, czy cURL pracuje dla Ciebie?
Tworzyć plik php i skopiuj tam:
Otwórz go z serwera. Jeśli wynik jest podobny do:
Tablica ( => 468736 => 3 => 3997 => 0 => 7.39.0 => x86_64-pc-win32 => OpenSSL/1.0.1j => 1.2.7.3 => Tablica ( => dict => plik => ftp => ftps => gopher => http => https => imap => imaps => ldap => pop3 => pop3s => rtsp => scp => sftp => smtp => smtps => telnet => tftp) )
Więc cURL jest w porządku, jeśli zamiast tego jest to błąd PHP, oznacza to problem.
Najpierw oczywiście sprawdź plik php.ini, znajdź tam linię
Rozszerzenie=php_curl.dll
I upewnij się, że nie jest poprzedzony średnikiem.
Jeśli tak jest, a cURL nie działa, można przeprowadzić kolejny test, aby potwierdzić nietypową sytuację. Utwórz kolejny plik php z zawartością:
Wyszukaj cURL w przeglądarce, jeśli jest tylko jedno dopasowanie, to moduł cURL nie jest załadowany:
Jednocześnie zarówno Apache, jak i PHP działają normalnie.
Trzy rozwiązania:
- Metoda pierwsza (niekoszerna). Jeśli masz PHP 5.6.*, weź wersję PHP 5.6.0, stamtąd weź stary plik php_curl.dll i zastąp go nowym z wersji takiej jak PHP 5.6.4. Dla tych z PHP 5.5.17 i nowszymi, musisz wziąć ten sam plik z PHP 5.5.16 i również go zastąpić. Jedynym problemem jest znalezienie tych starych wersji. Można oczywiście poszperać w http://windows.php.net/downloads/snaps/php-5.6 , ale osobiście nie znalazłem tam tego, czego potrzebowałem. A sama decyzja jest jakoś nie do końca koszerna.
- Druga metoda (bardzo szybka, ale też niekoszerna). Skopiuj plik libssh2.dll z katalogu PHP do katalogu Apache24bin i uruchom ponownie Apache.
- Metoda trzecia (koszerna - ludzie koszerni biją brawo na stojąco). Musisz dodać swój katalog PHP do PATH. Jak to zrobić, jest bardzo dobrze opisane w oficjalnej dokumentacji.
Sprawdzamy:
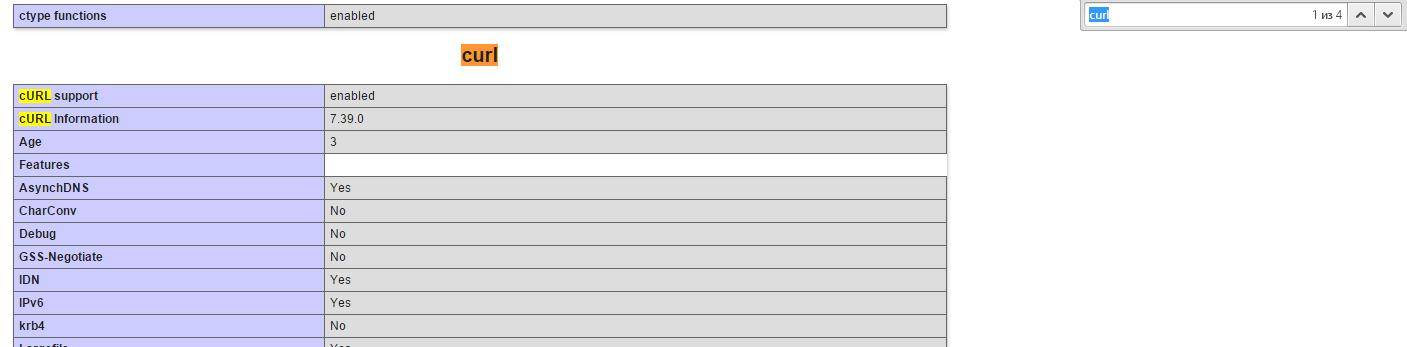
Voila, sekcja cURL jest na swoim miejscu.
Dlaczego? Skąd wziął się ten problem? Na to pytanie nie ma odpowiedzi, choć mechanizm jego powstawania został już opisany.
Problem wydaje się być związany z faktem, że 5.6.1 miało zostać wydane ze zaktualizowaną wersją libcurl 7.38.0. Ale nie jest to pewne, autorzy PHP kiwają głową na Apache, mówiąc, że jest tam kilka błędów.
Mechanizm problemu: jeśli katalog PHP nie jest zawarty w systemowej PATH, to przy uruchomieniu usługi Apache nie jest w stanie znaleźć nowej biblioteki dll (libssh2.dll), która jest zależnością dla php_curl.
Istotne raporty o błędach:
Błąd krytyczny: wywołanie niezdefiniowanej funkcji curl_multi_init() w ...
Ogólnie rzecz biorąc, były problemy z cURL w PHP, wydaje się, że jeśli nie zawsze, to bardzo często. W trakcie googlowania mojego problemu natknąłem się na wątki, z których niektóre mają kilkanaście lat.
Ponadto googlowanie dało jeszcze kilka wniosków:
W Internecie jest wystarczająco dużo "instrukcji dla kretynów", w których szczegółowo opowiadają obrazkami, jak odkomentować linię extension=php_curl.dll w pliku php.ini.
Na oficjalnej stronie PHP, w sekcji dotyczącej instalacji cURL, znajdują się tylko dwie sugestie dotyczące systemu Windows:
Aby pracować z tym modułem w Pliki Windows libeay32.dll i ssleay32.dll muszą istnieć w systemowej zmiennej środowiskowej PATH. Nie potrzebujesz pliku libcurl.dll ze strony cURL.
Przeczytałem je dziesięć razy. Przełączony język angielski i przeczytaj go jeszcze kilka razy po angielsku. Za każdym razem coraz bardziej przekonywałem się, że te dwa zdania zostały napisane przez zwierzęta, czy ktoś po prostu wskoczył na klawiaturę – nie rozumiem ich znaczenia.
Jest też kilka szalonych wskazówek i instrukcji (niektóre nawet udało mi się wypróbować).
Na stronie z raportami o błędach PHP byłem już bliski rozwikłania potrzeby włączenia katalogu z PHP w zmiennej systemowej PATH.
Ogólnie dla tych, którzy mają problem z cURL i którzy muszą „dołączyć katalog z PHP do zmiennej systemowej PATH”, przejdź do instrukcji wspomnianej powyżej http://php.net/manual/en/faq.installation .php#faq .instalacja.addtopath . Wszystko jest proste, a co najważniejsze ludzki język co należy zrobić, jest napisane.