Astăzi, aș dori să vorbesc puțin mai mult despre tehnologia SMART menționată în articolul precedent cu privire la criteriile de alegere a unui hard disk, precum și să aflu problema apariției sectoarelor defecte la verificarea suprafeței cu programe speciale și epuizare. suprafața de rezervă pentru realocarea lor - întrebare ridicată din ultimul articol.
Pentru început, ca întotdeauna, o scurtă digresiune istorică. Fiabilitatea unui hard disk (și a oricărui dispozitiv de stocare în sensul cel mai general) este întotdeauna de cea mai mare importanță. Iar ideea nu este deloc costul ei, ci valoarea informațiilor pe care le ia cu ea într-o altă lume, lăsând viața însăși și pierderea de profit asociată cu timpul de nefuncționare atunci când hard disk-urile eșuează, dacă vorbim de utilizatori de afaceri, chiar dacă informaţia rămâne. Și este destul de firesc să vrei să știi din timp despre astfel de momente neplăcute. Chiar și raționamentul obișnuit la nivel de gospodărie sugerează că monitorizarea stării dispozitivului în funcțiune poate sugera astfel de momente. Rămâne doar să implementăm cumva această observație în hard disk.
Pentru prima dată, inginerii gigantului albastru (IBM, adică) s-au gândit la această sarcină. Și în 1995, au propus o tehnologie care monitorizează câțiva parametri critici ai unității și încearcă să prezică defecțiunea acestuia pe baza datelor colectate - Analiza predictivă a defecțiunilor (PFA). Ideea a fost preluată de Compaq, care ulterior și-a creat propria tehnologie - IntelliSafe. Seagate, Quantum și Conner au participat, de asemenea, la dezvoltarea Compaq. Tehnologia creată de ei a monitorizat, de asemenea, o serie de caracteristici de performanță a discului, le-a comparat cu o valoare acceptabilă și a raportat sistemului gazdă dacă a existat un pericol. Acesta a fost un pas uriaș înainte, dacă nu în creșterea fiabilității hard disk-urilor, atunci cel puțin în reducerea riscului de pierdere a informațiilor la utilizarea lor. Primele încercări au avut succes și au arătat necesitatea dezvoltării în continuare a tehnologiei. Deja în uniunea tuturor producătorilor majori de hard disk a apărut tehnologia SMART (Self Monitoring Analysing and Reporting Technology), bazată pe tehnologiile IntelliSafe și PFA (apropo, PFA încă există ca un set de tehnologii de monitorizare și analiză a diferitelor subsisteme de Serverele IBM, inclusiv subsistemul disc, iar monitorizarea acestuia din urmă se bazează tocmai pe tehnologia SMART).
Deci, SMART este o tehnologie pentru evaluarea internă a stării unui disc și un mecanism pentru prezicerea unei posibile defecțiuni a unui hard disk. Este important de menționat că tehnologia, în principiu, nu rezolvă problemele emergente (cele principale sunt prezentate în figura de mai jos), poate doar avertiza despre o problemă care a apărut deja sau este așteptată în viitorul apropiat.
În același timp, trebuie spus, de asemenea, că tehnologia nu este capabilă să prezică absolut toate problemele posibile, iar acest lucru este logic: ieșirea electronicii ca urmare a unei supratensiuni, deteriorarea capetelor și a suprafețelor ca urmare a unei impact, etc. nicio tehnologie nu poate prezice. Previzibile sunt doar acele probleme care sunt asociate cu deteriorarea treptată a oricăror caracteristici, degradarea uniformă a oricăror componente.
Etapele dezvoltării tehnologiei
Tehnologia SMART a trecut prin trei etape în dezvoltarea sa. În prima generație a fost implementată observarea unui număr mic de parametri. Nu au fost furnizate acțiuni independente ale unității. Lansarea a fost efectuată numai prin comenzi de pe interfață. Nu există nicio specificație care să descrie standardul complet și, prin urmare, nu a existat și nu există un destin clar despre parametrii care ar trebui controlați. Mai mult decât atât, definirea lor și determinarea nivelului admisibil de reducere a acestora a fost lăsată în întregime la latitudinea producătorilor de hard disk (ceea ce este firesc datorită faptului că producătorul știe mai bine ce anume trebuie controlat de hard disk-ul dat, deoarece toate hard disk-urile unitățile sunt prea diferite). Și software-ul, din acest motiv, scris, de regulă, de companii terțe, nu era universal și putea raporta în mod eronat o eșec iminent (confuzia a apărut din cauza faptului că diferiți producători au stocat valorile diferiților parametri sub același identificator). Au existat un număr mare de plângeri că numărul cazurilor de detectare a unei stări pre-defecțiune este extrem de mic (particularități ale naturii umane: vrei să obții totul dintr-o dată, nimănui nu i-a trecut cumva prin minte să se plângă de defecțiuni bruște de disc înainte introducerea SAMRT). Situația a fost agravată de faptul că în majoritatea cazurilor nu au fost îndeplinite cerințele minime pentru funcționarea SMART (vom vorbi despre asta mai târziu). Statisticile arată că numărul de eșecuri prezise a fost mai mic de 20%. Tehnologia în acest stadiu era departe de a fi perfectă, dar a fost un pas înainte revoluționar.
Nu se știu multe despre a doua etapă a dezvoltării SMART - SMART II. Practic, au fost observate aceleași probleme ca la prima. Inovațiile au fost posibilitatea unei verificări de fundal a suprafeței, efectuată automat de disc în timpul inactiv și înregistrarea erorilor, lista parametrilor controlați a fost extinsă (din nou, în funcție de model și producător). Statisticile arată că numărul defecțiunilor previzibile a ajuns la 50%.
Etapa modernă este reprezentată de tehnologia SMART III. Ne vom opri asupra ei mai detaliat, vom încerca să înțelegem în termeni generali cum funcționează, de ce și de ce este necesar.
Știm deja că SMART monitorizează principalele caracteristici ale unității. Acești parametri se numesc atribute. Parametrii necesari pentru monitorizare sunt determinați de producător. Fiecare atribut are o anumită valoare - Valoare. De obicei, variind de la 0 la 100 (deși poate fi până la 200 sau 255), valoarea sa este fiabilitatea unui anumit atribut în raport cu unele dintre valorile sale de referință (determinate de producător). O valoare ridicată indică nicio modificare a acestui parametru sau, în funcție de valoare, deteriorarea lui lentă. O valoare scăzută indică o degradare rapidă sau o posibilă defecțiune în curând, de exemplu. cu cât valoarea atributului Value este mai mare, cu atât mai bine. Unele programe de monitorizare afișează valoarea brută sau valoarea brută - aceasta este valoarea atributului în format intern (care este diferit și pentru discuri de diferite modele și diferiți producători), în care este stocat în unitate. Pentru un simplu utilizator, nu este foarte informativ, valoarea Value calculată din acesta prezintă un interes mai mare. Pentru fiecare atribut, producătorul definește valoarea minimă posibilă la care este garantată funcționarea fără defecțiuni a unității - Prag. Dacă valoarea atributului este sub valoarea Prag, este foarte probabilă o defecțiune sau o defecțiune completă. Rămâne doar să adăugăm că atributele sunt critice și non-critice. Dacă un parametru de importanță critică depășește pragul, valoarea reală înseamnă eșec, dacă un parametru necritic depășește valorile permise, indică o problemă, dar discul poate încă funcționa (deși, poate, cu o oarecare deteriorare a unor caracteristici : performanță, de exemplu).
Caracteristicile critice observate cel mai frecvent sunt: Raw Read Error Rate - rata erorilor la citirea datelor de pe un disc, a căror origine se datorează hardware-ului discului.
Timp de învârtire- timpul pentru a învârti un pachet de discuri de la viteza de repaus la viteza de operare. Când se calculează valoarea normalizată (Valoare), timpul practic este comparat cu o valoare de referință setată din fabrică. O valoare non-maximă care nu se deteriorează cu Valoarea numărului de reîncercări Spin Up = max (Raw egal cu 0) nu înseamnă nimic rău. Diferența de timp față de referință poate fi cauzată de o serie de motive, de exemplu, sursa de alimentare ne-a dezamăgit.
Număr de reîncercări de învârtire- numărul de încercări repetate de rotire a discurilor la viteza de funcționare, dacă prima încercare nu a reușit. O valoare brută diferită de zero (respectiv, o valoare non-maximum) indică probleme în partea mecanică a unității.
Seek Error Rate- frecventa erorilor de pozitionare a blocului de capete. O valoare Raw ridicată indică prezența unor probleme, care pot fi servo-uri deteriorate, dilatarea termică excesivă a discurilor, probleme mecanice în unitatea de poziționare etc. O valoare constant ridicată indică faptul că totul este în regulă.
Număr de sectoare realocate- numărul operațiunilor de redistribuire a sectorului. SMART în cele moderne este capabil să analizeze sectorul pentru stabilitate din mers și, dacă este recunoscut ca un eșec, să-l reatribuie. Mai jos vom vorbi despre asta mai detaliat.
Dintre atributele informaționale necritice, ca să spunem așa, următoarele sunt de obicei monitorizate:
Toate erorile și modificările parametrilor care apar sunt înregistrate în jurnalele SMART. Această posibilitate a apărut deja în SMART II. Toți parametrii revistelor - scopul, dimensiunea, numărul lor sunt determinați de producătorul hard diskului. Momentan, ne interesează doar faptul prezenței lor. Fara detalii. Informațiile stocate în jurnalele sunt folosite pentru a analiza starea și a face prognoze.
Dacă nu intrați în detalii, atunci munca SMART este simplă - în timpul funcționării unității, toate erorile și fenomenele suspecte care apar sunt pur și simplu urmărite, care se reflectă în atributele corespunzătoare. În plus, începând cu SMART II, multe unități au funcții de autodiagnosticare. Testele SMART pot fi lansate în două moduri, off-line - testul este de fapt efectuat în fundal, deoarece unitatea este gata să accepte și să execute o comandă în orice moment, și exclusiv, în care atunci când se primește o comandă, testul execuția se încheie.
Sunt documentate trei tipuri de teste de autodiagnosticare: colectarea datelor de fundal (colectare off-line), test scurtat (Short Self-test), test extins (Extended Self-test). Ultimele două pot rula atât în fundal, cât și în moduri exclusive. Setul de teste incluse în acestea nu este standardizat.
Durata executării lor poate fi de la secunde la minute și ore. Dacă brusc nu accesați discul și, în același timp, scoate sunete ca în timpul unei sarcini de lucru - pare să facă introspecție. Toate datele colectate în urma unor astfel de teste vor fi, de asemenea, stocate în jurnale și atribute.
Oh, acele sectoare rele...
Acum să revenim la problema sectoarelor proaste, care a început totul. SMART III are o caracteristică care vă permite să reatribuiți în mod transparent sectoarele DAU pentru utilizator. Mecanismul funcționează destul de simplu, cu o citire instabilă a unui sector, sau o eroare la citirea acestuia, SMART îl introduce în lista celor instabile și mărește contorul acestora (Current Pending Sector Count). Dacă sectorul este citit fără probleme în timpul accesului repetat, acesta va fi eliminat din această listă. Dacă nu, atunci când i se oferă ocazia - în absența accesului la disc, discul va începe o verificare independentă a suprafeței, în special a sectoarelor suspecte. Dacă sectorul este recunoscut ca fiind rău, atunci acesta va fi realocat sectorului de pe suprafața de rezervă (respectiv, RSC va crește). O astfel de remapare de fundal duce la faptul că pe hard disk-urile moderne, sectoarele defecte nu sunt aproape niciodată vizibile atunci când se verifică suprafața cu programe de service. În același timp, cu un număr mare de sectoare defectuoase, realocarea acestora nu poate continua la nesfârșit. Primul limitator este evident - acesta este volumul suprafeței de rezervă. Acesta este cazul pe care l-am avut în vedere. Al doilea nu este atât de evident - adevărul este că hard disk-urile moderne au două liste de defecte P-list (Primar, din fabrică) și G-list (Growth, format direct în timpul funcționării). Și cu un număr mare de realocări, se poate dovedi că nu există niciun loc în lista G pentru a înregistra o nouă reatribuire. Această situație poate fi identificată printr-o rată ridicată de sectoare remapate în SMART. În acest caz, nu totul este pierdut, dar asta depășește domeniul de aplicare al acestui articol.
Deci, folosind datele SMART, fără să duceți discul la atelier, puteți spune destul de precis ce se întâmplă cu el. Există diverse tehnologii suplimentare pentru SMART care vă permit să determinați starea discului și mai precis și aproape fiabil cauza defecțiunii acestuia. Despre aceste tehnologii vom vorbi într-un articol separat.
Trebuie să știți că achiziționarea unei unități cu SMART nu este suficientă pentru a fi conștienți de toate problemele care apar cu unitatea. Discul, desigur, își poate monitoriza starea fără ajutor extern, dar nu va putea să se avertizeze singur în cazul în care se apropie un pericol. Ai nevoie de ceva care să îți permită să emiti un avertisment bazat pe date SMART. (lanțul obișnuit este prezentat în figura de mai jos).
Alternativ, este posibil BIOS-ul care, la pornirea cu opțiunea corespunzătoare activată, verifică starea unităților SMART. Și dacă doriți să monitorizați în mod constant starea discului, trebuie să utilizați un fel de program de monitorizare. Apoi puteți vedea informațiile într-un mod detaliat și convenabil.

SmartMonitor de la HDD Speed care rulează sub DOS

SIGuiardian rulează de pe Windows
Despre aceste programe vom vorbi și într-un articol separat. La asta mă refeream când spuneam că la început nu au fost îndeplinite cerințele necesare la operarea hard disk-urilor cu SMART.
Tehnologii de stocare a informațiilor:
Tehnologia NoiseGuardTehnologii magneto-optice
La afișarea parametrilor S.M.A.R.T, Valoarea trebuie să depășească Pragul (valoarea parametrului critic), această valoare trebuie să fie mare.
Un marcator de atribut verde indică faptul că parametrul de atribut este normal.
Marcatorul galben indică o ușoară discrepanță.
Roșu - acestea sunt discrepanțe puternice, cu acest parametru hard disk-ul poate eșua în orice minut, stocarea datelor pe el este nesigură.
Rata de eroare de citire brută- acest atribut afișează rata de eroare la citirea de pe disc.
Timp de învârtire- un atribut al promovării discului la starea de funcționare, o sursă de alimentare de proastă calitate poate afecta diferența cu valoarea de referință.
Pornire/Oprire numărătoare- numărul de porniri și opriri ale hard diskului.
Număr de sectoare realocate- contorul de sectoare realocate, care arata numarul de sectoare de rezerva capabile sa le inlocuiasca pe cele proaste, cel mai semnificativ parametru pentru performanta hard disk-ului. Când sistemul de hard disk detectează o eroare de citire/scriere, sectorul este suprascris în zona de rezervă, acest parametru arată cel mai clar performanța hard diskului și, cel mai important, acest atribut nu poate fi corectat de niciun program. Cu un indicator extrem de scăzut al acestui parametru, merită să vă gândiți la schimbarea hard disk-ului.
Seek Error Rate- valoarea frecvenței erorilor în poziționarea capetelor, informează despre supraîncălzirea hard disk-ului sau o poziție instabilă în coș, soluția este posibilă într-o fixare mai fiabilă a hard disk-ului.
Număr de ore de pornire- un atribut care afișează numărul de ore în starea pornit.
Număr de reîncercări de rotire- numărul de repetări de rotire a discului în cazul unui precedent nereușit.
Încercări de recalibrare- acest atribut indică câte repetări de calibrare s-au făcut, cu condiția ca prima încercare să fie nereușită. Indică probleme cu partea mecanică a hard diskului.
Număr de cicluri de alimentare a dispozitivului- numărul de cicluri complete de pornire/oprire a dispozitivului.
Număr de retrageri de urgență- atribut parcare cap in caz de urgenta, pierdere a puterii sau scadere puternica a acesteia, se intampla cand conectorul de alimentare este prost conectat sau se defecteaza placa HDD.
Număr de cicluri de încărcare/descărcare- numarul de cicluri de aducere a capetelor in pozitia de lucru.
Temperatura HDA- Temperatura hard disk.
Număr de evenimente de realocare- contorul operațiunilor de remapare, arată numărul de încercări de transfer a sectoarelor defectuoase în zona de rezervă.
Număr de erori curente în așteptare- un contor de sectoare a căror citire este dificilă, aceste sectoare includ sectoare care nu au putut fi citite prima dată, așa-numitele blocuri defectuoase, este posibil să-l repare scriindu-le forțat informații și citindu-le, această procedură poate fi realizat de programul HddScan.
Număr de erori necorectabile- contor de erori necorectabile, indică defecte la suprafața hard disk-ului.
Erori UltraDMA CRC- erori de interfață externă care apar atunci când cablul SATA este de proastă calitate.
Rata de eroare multizonă- frecvența de apariție a erorilor la înregistrarea datelor.
Hard disk-urile moderne sunt dispozitive destul de „inteligente” și, pe lângă proprietățile lor de bază inerente ca dispozitive de stocare și procesare a datelor, suportă tehnologia de autotestare, analiză a stării și acumularea de date statistice privind deteriorarea lor. propriile caracteristici INTELIGENT. (S elf- M monitorizarea A analiză A nd R raportare T ecnologie). Bazele S.M.A.R.T. au fost dezvoltate în 1995 prin eforturile comune ale producătorilor de top de hard disk-uri (HDD). În anii următori, standardele S.M.A.R.T au fost perfecţionate în conformitate cu schimbările de tehnologie şi echipamente (SMART II şi SMART III) şi continuă să se îmbunătăţească în prezent.
Un hard disk, începând din momentul fabricării sale, monitorizează constant anumiți parametri ai stării sale și îi reflectă în caracteristici speciale - atribute(Atribut), stocat într-un dispozitiv de stocare permanent, de regulă, într-o parte special alocată a suprafeței discului, accesibilă numai firmware-ului intern al unității - zonă servicii. Datele de atribut pot fi citite, conform specificației ATA ( LA A atachment) prin comenzi de suport SMART (SMART READ DATA și mai mult de o duzină de comenzi), care sunt transferate pe unitate prin software special, cum ar fi utilități de la producătorii de echipamente sau programe universale de testare și monitorizare HDD (discuri, smartctl, GSmartControl, gnome-). discuri etc.). Standardele moderne ATA includ suport pentru protocolul SCT (SMART Command Transport), care citește jurnalele de statistici ale dispozitivului. Jurnalul de statistici al dispozitivului este un jurnal SMART numai pentru citire trimis de unitate atunci când primește comenzi READ LOG EXT, READ LOG DMA EXT sau SMART READ LOG.
Atributul este o caracteristică a unei anumite stări a hard disk-ului, care se modifică în timpul funcționării, luând o valoare numerică de la valoarea maximă setată la momentul fabricării acestui dispozitiv, până la valoarea minimă, la atingerea căreia performanța a unității nu este garantată. Toate atributele sunt identificate prin numărul lor digital, majoritatea fiind interpretate în același mod de hard disk-uri de modele diferite. Unele dintre ele pot fi utilizate numai de un anumit producător de hardware și sunt acceptate de anumite modele de unități. Deci, de exemplu, un atribut cu id 7 , care caracterizează numărul de erori în instalarea capetelor pe pista necesară a suprafeței discului Seek_Error_Rate nu are sens pentru unitățile cu stare solidă (SSD) și, în consecință, nu este acceptat de acestea, iar atributul cu identificatorul 9 care caracterizează timpul total de funcţionare al acţionării pentru întreaga perioadă de funcţionare şi notat ca Power_On_Hours, acceptat atât de SSD, cât și de HDD tradițional.
Atributele constau din mai multe câmpuri (denumite cel mai frecvent ca Val, Worst, Tresh, RAW), fiecare dintre acestea fiind un indicator specific care caracterizează starea tehnică a unității la un moment dat. Cititorii S.M.A.R.T afișați conținutul atributelor, de obicei sub forma mai multor coloane:
Pre-eșec (PF, 01h)- când este atinsă valoarea de prag a acestui tip de atribut, discul trebuie înlocuit. Uneori, acest bit de steaguri este notat ca Viață critică (CR) sau Garanție înainte de eșec (PW)
O test nline (OC, 02h) - atributul actualizează valoarea atunci când efectuează teste SMART încorporate off-line / on-line;
P erfomance R exaltat (PE sau PR , 04h) – atribut caracterizează performanța;
E rror R ate (ER , 08h) – atributul reflectă contoarele de erori hardware;
E aerisire C ounts (EC, 10h) - atributul este un contor de evenimente;
S elf P rezervare (SP, 20h) - atribut de autorezervare;
Unele dintre programe pot interpreta steagurile ca descrieri textuale care sunt similare ca semnificație cu cele discutate mai sus. Un atribut poate avea mai multe valori setate la unul, de exemplu, un atribut cu id 05
reflectând numărul de sectoare realocate din cauza defecțiunilor din zona de rezervă, are setați steagurile SP + EC + OC - auto-salvare, contor de evenimente, actualizat când unitatea este offline și online.
Pentru a analiza starea unității, poate cea mai importantă valoare a atributului este valoare- număr condiționat (de obicei de la 0 la 100 sau până la 253) stabilit de producător. Sens valoare este setat inițial la maxim atunci când unitatea este fabricată și scade pe măsură ce unitatea se degradează. Pentru fiecare atribut, există o valoare prag, la atingerea căreia producătorul nu garantează performanța acesteia - câmpul Prag. Dacă valoarea valoare apropiindu-se sau coborând mai jos Prag, - este timpul să schimbați unitatea.
Lista de atribute și valorile lor nu sunt standardizate în mod rigid și unele dintre ele pot fi determinate de producătorul unității, dar cele mai multe dintre ele sunt interpretate în același mod. De exemplu, un atribut cu id 05 (număr de sectoare realocate) va caracteriza numărul de sectoare de disc respinse și realocate din zona de rezervă, atât pentru dispozitivele fabricate de Seagate Technology, cât și pentru dispozitivele fabricate de Western Digital. Setul de atribute acceptate depinde de modelul de unitate și poate varia semnificativ în compoziție pentru diferite modele.
Cel mai comun instrument pentru obținerea datelor S.M.A.R.T într-un mediu Linux este utilitarul smartctl din trusa smartmontools, de obicei incluse în software-ul implicit al oricărei distribuții. Dacă este necesar, puteți actualiza versiunea, precum și descărca documentația în limba engleză, pe site-ul web al proiectului smartmontools.org.
Pentru a lucra cu utilitarul smartctl sunt necesare drepturi de superutilizator rădăcină.
format de linie de comandă smartctl:
opțiunile dispozitivului smartctl
Exemple de utilizare smartctl
smartctl --help sau smartctl --usage- afișați un indiciu despre utilizarea comenzii.
Parametrii smartctl:
-V, --versiune, --drept de autor, --licență- afișare informații despre versiunea, drepturile de autor și licența.
-i, --info- afișați informații de identificare pentru dispozitiv.
-g NUME, --get=NUME- afișați opțiunile setărilor discului (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --toate- afișați toate datele SMART ale unității specificate.
-x, --xall- afișați toate datele tehnice pentru unitatea specificată.
--scanare- căutați dispozitive de disc.
-q TYPE, --quietmode=TIP setați modul de verbositate de ieșire pentru smartctl (numai erori, silentios, noserial)
-d TYPE, --device=TYPE- setați tipul dispozitivului (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N /E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) smartctl nu o pot determina automat.
-b TIP, --badsum=TIP- setați reacția la detectarea erorilor de sumă de control (avertizare, ieșire, ignorare)
-r TIP, --report=TIP- opțiune destinată dezvoltatorilor smartmontoolsși vă permite să obțineți informații detaliate atunci când efectuați tranzacții ale funcției de control al dispozitivului I/O ioctls(ioctl, ataioctl, scsiioctl și nivel de depanare). Detalii - om smartctl
-n MOD, --nocheck=MOD- modul de interzicere de a efectua teste pentru modurile de economisire a energiei (niciodată, somn, standby, inactiv). Utilizat de obicei pentru a preveni pornirea motorului axului cu comanda smartctl.
-s VALOARE, --smart=VALOARE- dezactivați sau activați SMART (pornit / dezactivat)
-o VALOR, --offlineauto=VALOARE- dezactivați sau activați execuția automată a testelor în modul non-interactiv (în modul drive inactiv), valori acceptate - on/off
-S VALOARE, --saveauto=VALOARE atribute de salvare automată (pornit/dezactivat)
-s NAME[,VALUE], --set=NAME[,VALUE]- dezactivați/activați parametrii hardware ai unității (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --sănătate- afișați starea unității (starea de sănătate SMART)
-c, --capacităţi- afișați informații despre capacitățile SMART acceptate ale hard disk-ului specificat.
-A, --atribute- afișați atribute SMART
-f FORMAT, --format=FORMAT- setați formatul atributelor SMART afișate (vechi, scurt, hex[,id|val]). Practic, afectează formatul valorilor afișate ale identificatorilor de atribute și formatul de afișare a steagurilor acestora:
vechi- Identificatorii de atribute sunt afișați în notație zecimală, valorile steagurilor sunt afișate în hexazecimal și interpretate ca text.
hex- la fel ca în cazul precedent, dar ID-urile atributelor sunt afișate în notație hexazecimală.
scurt- ieșire compactă, identificatorii sunt afișați în notație zecimală, steaguri sunt afișate ca caractere cu decodare în partea de jos a tabelului:
ID# ATTRIBUTE_NAME FLAGS VALORE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029 . . . . . . 254 Senzor_de_cădere_liberă -O--CK 100 100 000 - 0 ||||||_ Păstrare automată K |||||__ Număr de evenimente C ||||___ Rata de eroare R |||____ Viteză/performanță S || ______ O actualizat online |______ P avertisment preeșec
-l TIP, --log=TIP- afișați jurnalul dispozitivului specificat (selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[, reset ], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPȚIUNE, --vendorattribute=N,OPȚIUNE- setați un parametru pentru un atribut definit de producător cu identificatorul N
-F TYPE, --firmwarebug=TIP- adaptarea programului pentru a ține cont de erorile din firmware-ul hardware al unității (niciunul, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TIP- opțiuni de disc prestabilite. În mod implicit, după ce au găsit informații despre unitate în baza de date, utilitarul smartctl, folosește setul de opțiuni disponibile pentru acest model. Opțiune utilizare- utilizați presetări pentru această unitate, ignora- nu folosi, spectacol- afișați presetări pentru acest disc, arata tot- afișare presetări pentru modelul specificat. Exemple:
smartctl -P ignoră /dev/hdb- ignora presetarile pentru /dev/hdb;
smartctl -P arată /dev/sdb- afișare presetări pentru unitatea specificată;
smartctl -P showall „ST9250315AS”- - presetări afișate pentru modelul de disc specificat - ST9250315AS;
smartctl -P showall „ST3750515AS” „SD15”- afișare presetări pentru modelul de disc specificat ST3750515AS cu firmware SD15;
-B [+]FIȘIER, --drivedb=[+]FIȘIER- citiți și modificați baza de date a modelelor de discuri din fișierul FILE. Semnul „+” în fața numelui fișierului înseamnă adăugarea de noi înregistrări în baza de date înaintea celor existente.
În mod implicit, baza de date este stocată în /usr/share/smartmontools/drivedb.h
OPȚIUNI DE AUTOTESTARE A DISPOZITIV =====
-t TEST, --test=TEST- porniți execuția testului TEST Run test. TEST: offline, scurt, lung, transport, forță, furnizor, N, select, M-N, în așteptare, N, afterselect,
-C, --captiv- executarea de teste în modul de captare a drive-ului. Folosit împreună cu parametrul -t pentru teste nuîn mod deconectat. Folosirea acestei opțiuni poate cauza ca dispozitivul să fie ocupat pe durata testului și poate duce la întreruperi ale sistemului și pierderi de date. Nu utilizați opțiunea -c pentru a efectua teste pe unități cu partiții montate. Pentru dispozitivele SCSI, această opțiune înseamnă rularea testelor încorporate în „Modul prim-plan” .
-X, --avort- forțați părăsirea unui test care rulează fără cheie --captiv.
Exemple de utilizare a smartctrl.
smartctl --info /dev/sdb- afișați informații de identificare pentru dispozitivul /dev/sdb. Exemplu de ieșire de comandă:
=== ÎNCEPEREA SECȚIUNII DE INFORMAȚII === Modelul dispozitivului: ST9500620NS Număr de serie: 9XF0AW8T Versiunea firmware: SN01 Capacitate utilizator: 500.107.862.016 octeți Dispozitivul este: Nu se află în baza de date smartctl Versiunea ATA este: 8 ATA Standard este: ATA-84-ACS Ora locală este: Tue Oct 28 15:05:31 2014 Suportul MSK SMART este: Disponibil - dispozitivul are capacitate SMART. Suportul SMART este: Activat
smartctl --all /dev/hda- afișați toate datele SMART pentru dispozitiv /dev/hda
Exemplu de date afișate:
=== ÎNCEPEREA SECȚIUNII DE INFORMAȚII === Modelul dispozitivului: ST9500620NS Număr de serie: 9XF0AW8T Versiunea firmware: SN01 Capacitate utilizator: 500.107.862.016 octeți Dispozitivul este: Nu se află în baza de date smartctl Versiunea ATA este: 8 ATA Standard este: ATA-84-ACS Ora locală este: Tue Oct 28 15:05:45 2014 Suportul MSK SMART este: Disponibil - dispozitivul are capacitate SMART. Suportul SMART este: Activat === ÎNCEPEREA SECȚIUNII DE CITIRE DATE INTELIGENTE === Rezultatul testului de autoevaluare a sănătății generale SMART: APROBAT Valori SMART generale: Starea de colectare a datelor offline: (0x82) Activitatea de colectare a datelor offline a fost finalizată fără eroare. Colectare automată de date offline: activată. Starea de execuție a autotestării: (0) Rutina de autotestare anterioară a fost finalizată fără eroare sau nu a fost executată vreodată niciun autotest. Timp total până la finalizarea colectării datelor offline: (634) secunde. Capacități de colectare a datelor offline: (0x7b) SMART execută Offline imediat. Suport activat/dezactivat pentru colectarea datelor offline automat. Suspendați colecția offline la o nouă comandă. Scanarea suprafeței offline este acceptată. Autotest acceptat. Autotestare a transportului acceptat. Autotest selectiv acceptat. Capacități SMART: (0x0003) Salvează datele SMART înainte de a intra în modul de economisire a energiei. Suportă temporizator SMART de salvare automată. Capacitatea de înregistrare a erorilor: (0x01) Înregistrarea erorilor este acceptată. Înregistrare cu scop general acceptat. Timp de sondare recomandat de rutină de autotestare scurtă: (1) minute. Durata de sondare recomandată pentru rutina de autotestare extinsă: (102) minute. Durata de votare recomandată de rutină de autotestare a transportului: (2) minute. Capacități SCT: (0x10bd) Stare SCT acceptată. SCT Feature Control acceptat. Tabel de date SCT acceptat. Atribute inteligente Număr de revizuire Număr de revizuire: 10 Furnizor specific atribute inteligente cu praguri: id # atribut_name value valoare cel mai prost de trei ori actualizat atunci când_failed raw_value 1 brut_read_error_rate 0x000f 082 064 044 Pre-eșec întotdeauna - 190 274 202 3 Spin_up_time 0x0003 096 096 000 Pre-Fail . Eșec întotdeauna - 0 12 Power_cycle_Count 0x0032 100 020 Old_age întotdeauna - 72 184 End-to-end_error 0x0032 100 100 099 Old_age Întotdeauna 0x0032 100 000 Old_age Întotdeauna - 0 188 Command_Timeout 0x0032 100 100 000 Old_age întotdeauna - 0 189 high_fly_write 0x003a 100 100 000 Bătrânețe Întotdeauna - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Bătrânețe Întotdeauna - 19 191 G-Sense_Error_Rate 0x0032. 0x0012 100.100.000 Old_age Always - 0198 Offline_Uncorectable 0x0010 100.100.000 Old_age Offline - 0199 UDMA_CRC_Error_Count 0x003e 200.200.2003e 200.200.2003e 200.2000000000000000000000SMART Numărul de revizuire al structurii de date a jurnalului de autotestare selectivă 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (Scanare 0x0) NU citiți-scanați restul discului. Dacă autotestarea selectivă este în așteptare la pornire, reluați după o întârziere de 0 minute.
smartctl -A -v 9,minute /dev/hda- afișați toate datele atributelor SMART pentru un dispozitiv /dev/hdași atributul cu id 9 (timpul de pornire) ar trebui interpretat ca o valoare internă dată în minute și nu în ore.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda- activați SMART pentru unitatea /dev/hda, permiteți teste automate offline și atribute de auto-salvare. Comanda poate fi executată pe un sistem care rulează. De fapt, aceasta este instalarea parametrilor de funcționare standard pentru o unitate de disc convențională.
smartctl --test=long /dev/hda- rulați teste încorporate extinse pentru unitatea /dev/hda.Comanda poate fi folosită pe un sistem care rulează. Pentru a vizualiza rezultatele executării testului, utilizați comanda pentru a afișa jurnalul intern după finalizarea testului.
smartctl -l autotest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had- Afișează datele din jurnalul de autotest intern și atributele de eroare.
smartctl -s on -t offline /dev/hdc- activați SMART și efectuați un test offline pentru unitatea /dev/hdc. Dacă se detectează o eroare în timpul testării, informațiile despre aceasta vor fi scrise în jurnalul intern, care poate fi vizualizat folosind parametrul -l eroare.
smartctl -q silent -a /dev/had- verificați datele SMART fără a afișa informațiile primite.Utilizat de obicei în scripturi. După executarea comenzii, codul de retur este verificat (variabilă $? shell de comandă) pentru a determina dacă valoarea oricărui atribut a depășit valoarea limită sau dacă există o intrare de eroare în jurnalele dispozitivului.
smartctl -q errorsonly -H -l autotest /dev/had- scoateți informații numai dacă există o condiție SMART eronată sau dacă oricare dintre testele interne eșuează.
smartctl -t select, 10-100 -t select, 30-300 -t afterselect, on -t pending, 45 /dev/hda- efectuați un test intern în zona specificată a blocurilor LBA și, după finalizarea acestuia, scanați restul discului. Dacă alimentarea este oprită în timpul scanării, continuați scanarea la 45 de minute după ce este pornită.
smartctl --all --device=3ware,0 /dev/sda- obțineți date SMART pentru primul disc ATA conectat la controlerul RAID 3ware.
smartctl -a -d 3ware,0 /dev/twe0- obțineți date SMART pentru primul disc ATA conectat la un controler RAID 3ware 6000/7000/8000.
smartctl -a -d 3ware,0 /dev/twa0- obțineți date SMART pentru primul disc ATA conectat la un controler RAID 3ware RAID 9000
smartctl -t short -d 3ware,3 /dev/sdb- rulați teste interne scurte pentru discul 4, al doilea dispozitiv SCSI de disc /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda- obțineți datele SMART ale discului conectat la canalul 3 al primului controler HighPoint RocketRAID
Explicația atributelor S.M.A.R.T
Identificatorii de atribut sunt dați în notație zecimală, iar cei din paranteze sunt în hexazecimal.
Evaluarea stării tehnice a hard disk-ului conform datelor S.M.A.R.T
Setul de atribute susținute de un anumit model de hard disk, chiar dacă este minim, vă permite să determinați starea tehnică și perspectivele de funcționare a dispozitivului cu fiabilitate ridicată. Puteți determina timpul petrecut în starea pornit după valoarea atributului 9 , și împreună cu valoarea atributului 12 - numărul de pornire / oprire și, prin urmare, - funcționare non-stop sau periodică. Intensitatea utilizării, condițiile de temperatură, influențele externe negative - toate aceste fapte sunt ușor de urmărit de valorile absolute ale atributelor corespunzătoare. În mod similar, puteți evalua nivelul de uzură a echipamentului, calitatea suprafeței și calea de scriere / citire.
Monitorizarea stării discului cu informații minime poate fi efectuată chiar și la nivel de BIOS. Dacă se atinge valoarea critică a oricărui atribut care caracterizează starea de sănătate, cu monitorizarea stării S.M.A.R.T activată în setările BIOS, încărcarea sistemului de operare este suspendată și pe ecran este afișat următorul mesaj:
Hard Disk principal principal: stare S.M.A.R.T RĂU!, Backup și înlocuire.
Apăsați F1 pentru a relua
Astfel, fără a instala sau a rula software suplimentar, este posibil să se determine în timp util starea critică a unității folosind sistemul de intrare-ieșire de bază (BIOS) atunci când computerul este pornit.
Starea tehnică a unui hard disk care nu a atins pragul critic este caracterizată de valoarea absolută a atributelor care reflectă contoarele de defecțiuni detectate și corectate de hardware-ul unității.
Modificarea valorilor absolute ale atributelor trebuie luată în considerare în dinamică și într-o relație logică între ele.
Rularea testelor S.M.A.R.T încorporate
Setul de teste S.M.A.R.T încorporate este determinat de producător și poate varia semnificativ pentru diferite modele de hard disk. Practic, testele SMART încorporate sunt teste scurte (short self-test) și lungi (sels-test extins). Testele scurte scanează o mică parte a suprafeței discului, așa cum este definită de producător, și rulează în medie aproximativ 1 minut. Testele lungi scanează întreaga suprafață de lucru a discului și pot rula, în funcție de viteza și volumul discului, chiar și pentru câteva ore. De asemenea, pentru discurile moderne, puteți efectua teste selective (autotest selectiv), ai căror parametri sunt stabiliți de utilizator și teste după transportul dispozitivului (autotest de transport). Testele pot fi anulate dacă modul de captare (captiv) al unității nu este setat și unitatea acceptă comanda de anulare a testului. În ceea ce privește modul de captare a unității atunci când rulează teste captiv, atunci trebuie să-l utilizați cu atenție dacă discul este folosit de sistem.
Exemple:
smartctl --test=short /dev/sdb- executați un scurt test. Ca răspuns la comandă, vor fi afișate informații:
=== ÎNCEPEREA SECȚIUNII IMMEDIATE ȘI AUTOTESTARE OFFLINE === Trimiterea comenzii: „Execuți imediat rutina de autotestare SMART Short în modul off-line”. Comanda de conducere „Executați rutina de autotestare scurtă SMART imediat în modul off-line” reușită. Testarea a început (testul anterior a fost anulat). Vă rugăm să așteptați 1 minut pentru finalizarea testului. Testul se va finaliza după vineri, 5 decembrie 16:08:09 2014 Utilizați smartctl -X pentru a anula testul.
Ceea ce înseamnă că a fost trimisă o comandă pe disc pentru a efectua un test scurt, discul a acceptat-o cu succes, testul va dura 1 minut și poți folosi comanda smartctl –X pentru a-l forța să se oprească.
Rezultatul executării testului poate fi verificat prin vizualizarea jurnalului de testare cu comanda smartctl –l autotest. Informațiile din jurnal vor fi primite ca răspuns autotestare:
=== ÎNCEPEREA SECȚIUNII DE CITIRE DATE INTELIGENTE === SMART Autotestare jurnalul de revizuire numărul 1 Num Test_Descriere Stare Durată de viață rămasă (ore) LBA_of_first_error # 1 Scurt offline Finalizat fără eroare 00% 831 -
Coloane de jurnal: Num- numar record.
Descriere Test- descrierea testului.
stare- stare de finalizare (finalizată fără erori)
Rămas- procentul de timp rămas până la sfârșitul testului, dacă acesta nu este încă finalizat (00%)
Durata de viață (ore)- timpul de funcționare a motorului de la începutul funcționării.
LBA_of_first_error- numărul blocului logic LBA la care a fost detectată prima eroare în timpul execuției testului. În acest exemplu, nu există erori.
Pentru a rula un test lung, utilizați comanda:
smartctl --test=long /dev/sdb
Ca răspuns la comandă, sunt afișate informații despre începutul testului:
=== ÎNCEPEREA SECȚIUNII IMMEDIATE ȘI AUTOTESTARE OFFLINE === Trimiterea comenzii: „Execută imediat rutina de autotestare extinsă SMART în modul off-line”. Comanda de conducere „Execută rutina de autotestare extinsă SMART imediat în modul off-line” reușită. Testarea a început. Vă rugăm să așteptați 70 de minute pentru finalizarea testului. Testul se va finaliza după vineri, 5 decembrie 17:15:44 2014
După cum puteți vedea, testul lung pentru acest model de unitate va rula timp de 70 de minute.
Rezultatul execuției poate fi verificat cu comanda smartctl –l selftest /dev/sda
Lista comenzilor ATA pentru lucrul cu S.M.A.R.T
Smart_read_values 0xd0 smart_read_thresholds 0xd1 Smart_Autosave 0xd2 Smart_save 0xd3 Smart_Imediad_offline 0xd4 smart_read_log_sector 0xd5 smart_write_log_sector 0xd6 Smart_Inable 0xd8 Smart_disable 0xd9 Smart_Status 0xda Smart_Auto_offline 0xdb
Mai multe despre subiectul hardware în Linux:
Mai devreme sau mai târziu (mai bine, desigur, dacă mai devreme) orice utilizator își pune întrebarea cât va dura hard disk-ul instalat pe computerul său și dacă este timpul să-i caute un înlocuitor. Nu este nimic surprinzător în asta, deoarece hard disk-urile, datorită caracteristicilor lor de design, sunt cele mai puțin fiabile dintre componentele computerului. În același timp, pe HDD majoritatea utilizatorilor stochează cea mai mare parte a celor mai diverse informații: documente, imagini, diverse programe etc., drept urmare o defecțiune neașteptată a discului este întotdeauna o tragedie. Desigur, este adesea posibil să recuperați informații de pe hard disk-uri „moarte” extern, dar este posibil ca această operațiune să vă coste un bănuț și să vă coste o mulțime de nervi. Prin urmare, este mult mai eficient să încerci să previi pierderea datelor.
Cum? Este foarte simplu... În primul rând, nu uitați de backup-urile obișnuite ale datelor și, în al doilea rând, monitorizați starea discurilor folosind utilități specializate. Vom lua în considerare mai multe programe ale unui astfel de plan în ceea ce privește sarcinile de rezolvat în acest articol.
Controlul parametrilor SMART și al temperaturii
Toate HDD-urile moderne și chiar și unitățile cu stare solidă (SSD) acceptă S.M.A.R.T. ( din engleza. Tehnologia de auto-monitorizare, analiză și raportare - tehnologie de auto-monitorizare, analiză și raportare), care a fost dezvoltată de marii producători de hard disk-uri pentru a crește fiabilitatea produselor lor. Această tehnologie se bazează pe monitorizarea și evaluarea continuă a stării hard disk-ului de către echipamentul de autodiagnosticare încorporat (senzori speciali), iar scopul ei principal este detectarea în timp util a unei posibile defecțiuni a unității.
Monitorizarea stării HDD în timp real
O serie de soluții de informare și diagnosticare pentru diagnosticarea și testarea hardware, precum și utilități speciale de monitorizare, utilizează S.M.A.R.T. pentru a monitoriza starea curentă a diferiților parametri vitali care descriu fiabilitatea și performanța hard disk-urilor. Ei citesc parametrii relevanți direct de la senzorii și senzorii termici cu care sunt echipate toate hard disk-urile moderne, analizează datele primite și le afișează sub forma unui raport tabel concis cu o listă de atribute. În același timp, unele dintre utilitare (Hard Drive Inspector, HDDlife, Crystal Disk Info etc.) nu se limitează la afișarea unui tabel de atribute (ale căror valori sunt de neînțeles pentru utilizatorii nepregătiți) și, în plus, afișează informații scurte. despre starea discului într-o formă mai înțeleasă.
Diagnosticarea stării unui hard disk folosind acest tip de utilități este la fel de ușoară ca decojirea perelor - trebuie doar să faceți cunoștință cu scurte informații de bază despre HDD-urile instalate: cu date de bază despre discuri în Hard Drive Inspector, un anumit procent condiționat de sănătatea hard diskului în HDDlife , indicatorul „Stare tehnică” din Crystal Disk Info ( Fig. 1), etc. Oricare dintre aceste programe oferă informațiile minime necesare despre fiecare dintre HDD-urile instalate pe computer: date despre modelul de hard disk, volumul acestuia, temperatura de funcționare, orele lucrate, precum și nivelul de fiabilitate și performanță. Aceste informații fac posibilă tragerea unor concluzii despre performanța mass-media.
Orez. 1. Informații scurte despre „sănătatea” HDD-ului care funcționează
Ar trebui să configurați lansarea utilitarului de monitorizare în același timp cu pornirea sistemului de operare, să ajustați intervalul de timp dintre verificările atributelor S.M.A.R.T. și să activați afișarea temperaturii și „nivelului de sănătate” al hard disk-urilor în tava de sistem. După aceea, pentru a controla starea discurilor, utilizatorul va trebui doar să arunce o privire la indicatorul din bara de sistem din când în când, care va afișa informații scurte despre starea unităților disponibile în sistem: nivelul lor de „sănătate”. şi temperatură (Fig. 2). Apropo, temperatura de funcționare nu este un indicator mai puțin important decât indicatorul condiționat al sănătății HDD, deoarece hard disk-urile se pot eșua brusc din cauza supraîncălzirii banale. Prin urmare, dacă hard disk-ul se încălzește peste 50 ° C, atunci ar fi mai înțelept să îi asigurăm răcire suplimentară.

Orez. 2. Afișare stare HDD
în tava de sistem cu programul HDDlife
Este de remarcat faptul că o serie de astfel de utilități oferă integrare cu Windows Explorer, datorită căreia o pictogramă verde este afișată pe pictogramele discurilor locale dacă acestea sunt în stare bună, iar dacă apar probleme, pictograma devine roșie. Deci, este puțin probabil să puteți uita de starea de sănătate a hard disk-urilor. Cu o astfel de monitorizare constantă, nu vei putea rata momentul în care încep să apară unele probleme cu discul, deoarece dacă utilitarul detectează modificări critice în S.M.A.R.T. și/sau temperatură, acesta va anunța cu atenție utilizatorul despre acest lucru (prin un mesaj pe ecran, un mesaj sonor etc. - Fig. 3). Datorită acestui lucru, va fi posibil să aveți timp să copiați datele de pe mediul care inspiră frică în avans.

Orez. 3. Un exemplu de mesaj despre necesitatea înlocuirii imediate a discului
Folosirea în practică a soluțiilor de monitorizare S.M.A.R.T. pentru a monitoriza starea hard disk-urilor este complet ușoară, deoarece toate astfel de utilități funcționează în fundal și necesită un minim de resurse hardware, astfel încât funcționarea lor nu va interfera în niciun caz cu fluxul principal de lucru.
Controlul atributelor S.M.A.R.T
Desigur, este puțin probabil ca utilizatorii avansați să se limiteze la evaluarea stării hard disk-urilor vizualizând un scurt verdict al unuia dintre utilitățile prezentate mai sus. Este de înțeles, deoarece prin decodarea atributelor S.M.A.R.T. este posibil să se identifice cauza defecțiunilor și, dacă este necesar, să se ia cu prudență unele măsuri suplimentare. Adevărat, pentru a controla în mod independent atributele S.M.A.R.T., va trebui să vă familiarizați cel puțin pe scurt cu S.M.A.R.T.
HDD-urile care acceptă această tehnologie includ rutine inteligente de autodiagnosticare, astfel încât acestea să poată „raporta” starea lor actuală. Aceste informații de diagnosticare sunt furnizate ca o colecție de atribute, adică caracteristici specifice ale hard diskului utilizate pentru a analiza performanța și fiabilitatea acestuia.
B despre Cele mai multe dintre atributele importante au aceeași semnificație pentru unitățile de la toți producătorii. Valorile acestor atribute în timpul funcționării normale a discului pot varia în anumite intervale. Pentru orice parametru, producătorul a definit o anumită valoare minimă de siguranță care nu poate fi depășită în condiții normale de funcționare. Determinați fără ambiguitate parametrii S.M.A.R.T critici și necritici pentru diagnosticare. problematic. Fiecare dintre atribute are propria sa valoare informațională și indică unul sau altul aspect în activitatea purtătorului. Cu toate acestea, în primul rând, ar trebui să acordați atenție următoarelor atribute:
- Raw Read Error Rate - frecvența erorilor în citirea datelor de pe disc din cauza defecțiunii echipamentului;
- Spin Up Time - timpul mediu de rotație al axului discului;
- Reallocated Sector Count - numărul de operațiuni de remapare a sectorului;
- Seek Error Rate - frecvența de apariție a erorilor de poziționare;
- Spin Retry Count - numărul de reîncercări de rotire a discurilor la viteza de operare dacă prima încercare eșuează;
- Current Pending Sector Count - numărul de sectoare instabile (adică sectoare care așteaptă procedura de remapare);
- Număr incorectabil de scanare offline - numărul total de erori necorectate în timpul operațiunilor de citire/scriere în sector.
De obicei, S.M.A.R.T. sunt afișate într-o formă tabelară cu numele atributului (Attribut), identificatorul acestuia (ID) și trei valori: curent (Valoare), pragul minim (Prag) și cea mai mică valoare a atributului pentru întreaga durată a unității (Worst) , precum și valoarea absolută a atributului (raw). Fiecare atribut are o valoare curentă, care poate fi orice număr între 1 și 100, 200 sau 253 (nu există un standard general pentru limitele superioare ale valorilor atributelor). Valorile Value și Worst pentru un hard disk complet nou sunt aceleași (Fig. 4).

Orez. 4. Atributele S.M.A.R.T. pe noul HDD
Prezentat în fig. Informațiile 4 ne permit să concluzionam că, pentru un hard disk teoretic sunet, valorile actuale (Valoare) și cele mai proaste (Cel mai proastă) ar trebui să fie cât mai aproape una de cealaltă posibil, iar valoarea brută pentru majoritatea parametrilor (cu excepția dintre parametrii: timpul de pornire, temperatura HDA și alții) ar trebui să fie aproape de zero. Valoarea curentă se poate modifica în timp, ceea ce reflectă în majoritatea cazurilor deteriorarea parametrilor hard disk descriși de atribut. Acest lucru poate fi văzut în fig. 5, care prezintă fragmente din tabelul de atribute S.M.A.R.T. pentru același disc - datele sunt primite cu un interval de jumătate de an. După cum puteți vedea, într-o versiune mai recentă a S.M.A.R.T. rata de eroare crescută la citirea datelor de pe disc (Raw Read Error Rate), a cărei origine se datorează hardware-ului discului și rata de eroare la poziționarea blocului de capete magnetice (Seek Error Rate), ceea ce poate indica supraîncălzirea a hard diskului și poziția instabilă a acestuia în coș . Dacă valoarea actuală a oricărui atribut se apropie sau devine mai mică decât pragul, atunci hard disk-ul este considerat nefiabil și ar trebui înlocuit de urgență. De exemplu, o scădere a valorii atributului Spin-Up Time (timpul mediu de rotație al axului discului) sub o valoare critică, de regulă, indică uzura completă a mecanicii, ca urmare a căreia discul nu mai poate menține viteza de rotație specificată de producător. Prin urmare, este necesară monitorizarea stării HDD-ului și periodic (de exemplu, o dată la 2-3 luni) efectuarea S.M.A.R.T. și salvați informațiile primite într-un fișier text. Pe viitor, aceste date pot fi comparate cu cele actuale și se pot trage anumite concluzii despre evoluția situației.
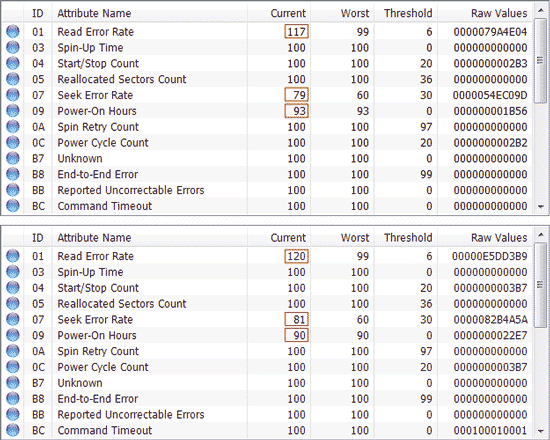
Orez. 5. Tabele de atribute S.M.A.R.T., obținute la intervale semianuale
(versiunea mai recentă a S.M.A.R.T. mai jos)
Când vizualizați atributele S.M.A.R.T., în primul rând, ar trebui să acordați atenție parametrilor critici, precum și parametrilor evidențiați cu alți indicatori decât culoarea de bază (de obicei albastru sau verde). În funcție de starea actuală a atributului din S.M.A.R.T. în tabel, de obicei este marcat într-o culoare sau alta, ceea ce face mai ușor de înțeles situația. În special, în programul Hard Drive Inspector, indicatorul de culoare poate fi verde, galben-verde, galben, portocaliu sau roșu - culorile verde și galben-verde indică faptul că totul este în regulă (valoarea atributului nu s-a schimbat sau s-a schimbat nesemnificativ), iar culorile galben, portocaliu și roșu semnalează pericol (cel mai rău dintre toate este roșul, care indică faptul că valoarea atributului a atins valoarea critică). Dacă oricare dintre parametrii critici este marcat cu o pictogramă roșie, atunci trebuie să înlocuiți de urgență hard disk-ul.
Să ne uităm la tabelul cu atributele S.M.A.R.T. ale aceluiași disc din programul Hard Drive Inspector, a cărui evaluare scurtă prin utilități de monitorizare a fost dată mai devreme. Din fig. 6 arată că valorile tuturor atributelor sunt normale și toți parametrii sunt marcați cu verde. Utilitarele HDDlife și Crystal Disk Info vor afișa o imagine similară. Adevărat, soluțiile mai profesionale pentru analiza și diagnosticarea HDD nu sunt atât de loiale și adesea etichetează mai meticulos atributele S.M.A.R.T. De exemplu, utilitare binecunoscute precum HD Tune Pro și HDD Scan, în cazul nostru, au fost suspecte de atributul UltraDMA CRC Errors, care afișează numărul de erori care apar atunci când informațiile sunt transmise prin interfața externă (Fig. 7). . Cauza unor astfel de erori este de obicei asociată cu un cablu SATA răsucit și de proastă calitate, care poate fi necesar să fie înlocuit.

Orez. 6. Tabel de atribute S.M.A.R.T., obținute în programul Hard Drive Inspector

Orez. 7. Rezultatele evaluării stării atributelor S.M.A.R.T
Utilitare HD Tune Pro și HDD Scan
Pentru comparație, să facem cunoștință cu atributele S.M.A.R.T. ale unui HDD foarte vechi, dar încă funcțional, cu probleme intermitente. El nu a inspirat încredere în programul Crystal Disk Info - în indicatorul „Stare tehnică”, starea discului a fost evaluată ca fiind alarmantă, iar atributul Reallocated Sector Count (sectoare reatribuite) s-a dovedit a fi evidențiat în galben (Fig. 8). Acesta este un atribut foarte important din punctul de vedere al „sănătății” discului, indicând numărul de sectoare remapate atunci când discul detectează o eroare de citire/scriere, în timpul acestei operațiuni, datele din sectorul defect sunt transferate în cel de rezervă. zonă. Culoarea galbenă a indicatorului de lângă parametru indică faptul că nu au mai rămas suficiente sectoare de rezervă cu care să le înlocuiți pe cele dăunătoare și, în curând, nu va mai fi nimic care să reatribuiască sectoarele proaste nou apărute. Să verificăm și modul în care soluții mai serioase evaluează starea discului, de exemplu, utilitarul HDDScan utilizat pe scară largă de profesioniști - dar aici vedem exact același rezultat (Fig. 9).
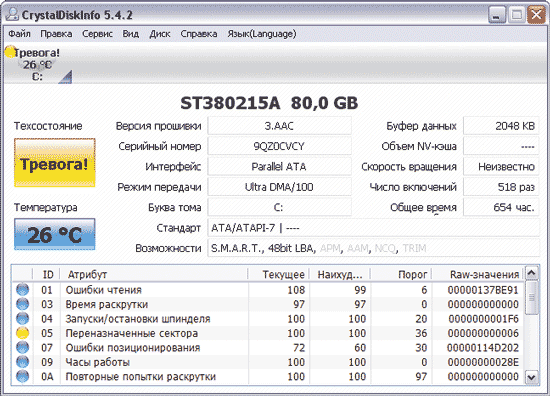
Orez. 8. Evaluați un hard disk problematic în CrystalDiskInfo

Orez. 9. Rezultatele diagnosticării HDD S.M.A.R.T. în HDDScan
Aceasta înseamnă că, evident, nu merită să tragi cu înlocuirea unui astfel de hard disk, deși poate servi încă ceva timp, deși, desigur, nu poți instala sistemul de operare pe acest hard disk. Trebuie remarcat faptul că, în prezența unui număr mare de sectoare realocate, viteza de citire / scriere scade (din cauza mișcărilor inutile pe care trebuie să le facă capul magnetic), iar discul începe să încetinească vizibil.
Scanarea suprafeței pentru sectoare defecte
Din păcate, în practică, un singur control al parametrilor SMART și al temperaturii nu este suficient. Când există cea mai mică dovadă că ceva nu este în regulă cu discul (în cazul înghețurilor periodice ale programului, de exemplu, la salvarea rezultatelor, citirea mesajelor de eroare etc.), trebuie să scanați suprafața discului pentru sectoare care nu pot fi citite. Pentru a efectua o astfel de verificare a suportului, puteți utiliza, de exemplu, utilitățile HD Tune Pro și HDDScan sau utilitățile de diagnosticare de la producătorii de hard disk, cu toate acestea, aceste utilitare funcționează numai cu modelele lor de hard disk și, prin urmare, nu vom lua în considerare lor.
Când utilizați astfel de soluții, există riscul coruperii datelor de pe discul scanat. Pe de o parte, cu informațiile de pe disc, dacă unitatea se dovedește cu adevărat a fi defectă, orice se poate întâmpla în timpul scanării. Pe de altă parte, este imposibil să se excludă acțiuni incorecte din partea utilizatorului, care începe din greșeală scanarea în modul de scriere, timp în care are loc suprascrierea sector cu sector a datelor de pe hard disk cu o anumită semnătură și pe baza viteza acestui proces, se face o concluzie despre starea hard disk-ului. Prin urmare, respectarea anumitor reguli de precauție este absolut necesară: înainte de a porni utilitarul, trebuie să creați o copie de rezervă a informațiilor și, în timpul verificării, să acționați strict conform instrucțiunilor dezvoltatorului software-ului corespunzător. Pentru a obține rezultate mai precise înainte de scanare, este mai bine să închideți toate aplicațiile active și să descărcați posibilele procese de fundal. În plus, trebuie avut în vedere că, dacă trebuie să testați HDD-ul sistemului, trebuie să porniți de pe o unitate flash și să începeți procesul de scanare de pe aceasta sau să scoateți complet hard disk-ul și să îl conectați la un alt computer de pe care să îl conectați. începeți să testați discul.
De exemplu, folosind HD Tune Pro, vom verifica suprafața HDD-ului pentru sectoare defecte, care mai sus nu au inspirat încredere în utilitarul Crystal Disk Info. În acest program, pentru a începe procesul de scanare, trebuie doar să selectați discul dorit, să activați fila scanare de eroareși faceți clic pe butonul start. După aceea, utilitarul va începe să scaneze secvențial discul, să citească sector cu sector și să marcheze sectoarele pe harta discului cu pătrate multicolore. Culoarea pătratelor, în funcție de situație, poate fi verde (sectoare normale) sau roșie (blocuri proaste), sau va avea o nuanță intermediară între aceste culori. După cum vedem din fig. 10, în cazul nostru, utilitatea nu a găsit blocuri defectuoase cu drepturi depline, dar, cu toate acestea, există un număr solid de sectoare cu una sau alta întârziere de citire (judecând după culoarea lor). În plus, în partea de mijloc a discului există un mic bloc de sectoare, a cărui culoare este aproape de roșu - aceste sectoare nu au fost încă recunoscute ca fiind proaste de către utilitate, dar sunt deja aproape de el și va intra în categoria celor rele în viitorul foarte apropiat.

Orez. 10. Scanarea suprafeței pentru sectoare defecte în HD Tune Pro
Testarea suportului media pentru sectoare proaste în programul HDDScan este mai dificilă și chiar mai periculoasă, deoarece în cazul unui mod selectat incorect, informațiile de pe disc se vor pierde iremediabil. În primul rând, pentru a începe scanarea, creați o nouă sarcină făcând clic pe butonul Sarcina nouași selectând comanda din listă Teste de suprafață. Apoi trebuie să vă asigurați că modul este selectat citit- acest mod este setat implicit și atunci când este utilizat, suprafața hard diskului este testată prin citire (adică fără ștergerea datelor). După aceea apăsați butonul Adaugă test(Fig. 11) și faceți dublu clic pe sarcina creată RD Citiți. Acum, în fereastra care se deschide, puteți observa procesul de scanare a discului pe grafic (Graph) sau pe hartă (Hartă) - fig. 12. La finalizarea procesului, vom obține aproximativ aceleași rezultate care au fost demonstrate mai sus de utilitarul HD Tune Pro, dar cu o interpretare mai clară: nu există sectoare proaste (sunt marcate cu albastru), dar există trei sectoare. cu un timp de raspuns de peste 500 ms (marcat cu culoarea rosie), care reprezinta un real pericol. În ceea ce privește cele șase sectoare portocalii (timp de răspuns de la 150 la 500 ms), acest lucru poate fi considerat în intervalul normal, deoarece o astfel de întârziere a răspunsului este adesea cauzată de interferențe temporare sub forma, de exemplu, a rulării programelor în fundal.

Orez. 11. Rulați un test de disc în HDDScan

Orez. 12. Rezultatele scanării unui disc în modul Citire folosind HDDScan
În plus, trebuie remarcat faptul că, dacă există un număr mic de blocuri dăunătoare, puteți încerca să îmbunătățiți starea hard disk-ului prin eliminarea sectoarelor defecte prin scanarea suprafeței discului în modul de înregistrare liniară (Erase) folosind programul HDDScan. După o astfel de operațiune, discul poate fi folosit în continuare o perioadă de timp, dar, desigur, nu ca disc de sistem. Cu toate acestea, nu trebuie să sperați la un miracol, deoarece HDD-ul a început deja să se prăbușească și nu există garanții că în viitorul apropiat numărul de defecte nu va crește și unitatea nu va eșua complet.
Programe de monitorizare S.M.A.R.T. și testare HDD
HD Tune Pro 5.00 și HD Tune 2.55
Dezvoltator: Software EFD
Mărimea distribuției: HD Tune Pro - 1,5 MB; HD Tune - 628 KB
Munca sub control: Windows XP/Server 2003/Vista/7
Metoda de distribuire: HD Tune Pro - shareware (demo de 15 zile); HD Tune - program gratuit (http://www.hdtune.com/download.html)
Preț: HD Tune Pro - 34,95 USD; HD Tune - gratuit (doar pentru uz necomercial)
HD Tune este un utilitar la îndemână pentru diagnosticarea și testarea HDD/SSD (vezi tabel), precum și a cardurilor de memorie, unităților USB și o serie de alte dispozitive de stocare. Programul afișează informații detaliate despre unitate (versiunea firmware, numărul de serie, dimensiunea discului, dimensiunea bufferului și modul de transfer de date) și vă permite să setați starea dispozitivului folosind S.M.A.R.T. și monitorizarea temperaturii. În plus, poate fi folosit pentru a testa suprafața discului pentru erori și pentru a evalua performanța dispozitivului prin efectuarea unei serii de teste (teste de viteză de citire/scriere secvențiale și aleatorii, test de performanță a fișierelor, test de cache și o serie de teste suplimentare) . De asemenea, utilitarul poate fi folosit pentru a configura AAM și pentru a șterge datele în siguranță. Programul este prezentat în două ediții: HD Tune Pro comercial și HD Tune gratuit și ușor. În ediția HD Tune, este disponibilă doar vizualizarea informațiilor detaliate despre disc și tabelul de atribute S.M.A.R.T., precum și scanarea discului pentru erori și testarea vitezei în modul de citire (Evaluare de nivel scăzut - citire).
Fila Sănătate este responsabilă de monitorizarea atributelor S.M.A.R.T. în program - datele sunt citite de la senzori după o perioadă de timp stabilită, rezultatele sunt afișate în tabel. Pentru orice atribut, puteți vizualiza istoricul modificărilor acestuia sub formă numerică și pe un grafic. Datele de monitorizare sunt înregistrate automat, dar nu sunt furnizate notificări de utilizator pentru modificări critice ale parametrilor.
În ceea ce privește scanarea suprafeței discului pentru sectoare defecte, fila este responsabilă pentru această operațiune. eroare Scanează. Scanarea poate fi rapidă (Scanare rapidă) și profundă - în timpul unei scanări rapide, nu este scanat întregul disc, ci doar o parte a acestuia (zona de scanare este determinată prin câmpurile Start și End). Sectoarele necorespunzătoare sunt afișate pe harta discului ca blocuri roșii.
HDDScan 3.3
Dezvoltator: Artem Rubtsov
Mărimea distribuției: 3,64 MB
Munca sub control: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Metoda de distribuire: program gratuit (http://hddscan.com/download/HDDScan-3.3.zip)
Preț: este gratuit
HDDScan este un utilitar pentru diagnosticarea de nivel scăzut a hard disk-urilor, unităților SSD și unităților flash USB. Scopul principal al acestui program este de a testa discurile pentru blocuri și sectoare defecte. De asemenea, utilitarul poate fi folosit pentru a vizualiza conținutul SMART, a monitoriza temperatura și a modifica unele setări ale hard diskului: managementul zgomotului (AAM), managementul energiei (APM), pornirea/oprirea forțată a axului unității etc. Programul funcționează fără instalare și poate fi lansat de pe medii portabile, cum ar fi unități flash.
Afișarea atributelor S.M.A.R.T. și monitorizarea temperaturii în HDDScan se face la cerere. Raportul S.M.A.R.T conține informații despre performanța și „sănătatea” unității sub forma unui tabel de atribute standard, temperatura unității este afișată în bara de sistem și într-o fereastră specială de informații. Rapoartele pot fi tipărite sau salvate ca fișier MHT. Sunt posibile testele S.M.A.R.T.
Suprafața discului este verificată în unul dintre cele patru moduri: Verificare (mod de verificare liniară), Citire (cititură liniară), Ștergere (scriere liniară) și Citire Fluture (mod de citire Fluture). Pentru a verifica discul pentru prezența blocurilor dăunătoare, se folosește de obicei un test în modul Citire, cu ajutorul căruia suprafața este testată fără a șterge datele (o concluzie despre starea unității se face pe baza vitezei sectorului- citirea datelor pe sectoare). La testarea în modul de înregistrare liniară (Erase), informațiile de pe disc sunt suprascrise, dar acest test poate vindeca într-o oarecare măsură discul, eliminându-l de sectoarele defecte. În oricare dintre moduri, puteți testa întregul disc sau un anumit fragment din acesta (zona de scanare este determinată prin specificarea sectoarelor logice inițiale și finale - Start LBA și, respectiv, End LBA). Rezultatele testului sunt prezentate sub forma unui raport (fila Raport) și afișate pe un grafic (Graph) și pe o hartă de disc (Hartă) indicând, printre altele, numărul de sectoare defecte (Bads) și sectoare al căror timp de răspuns în timpul testarea a durat mai mult de 500 ms (marcat cu roșu).
Hard Drive Inspector 4.13
Dezvoltator: AltrixSoft
Mărimea distribuției: 2,64 MB
Munca sub control: Windows 2000/XP/2003 Server/Vista/7
Metoda de distribuire: shareware (demo de 14 zile - http://www.altrixsoft.com/ru/download/)
Preț: Hard Drive Inspector Professional - 600 de ruble; Hard Drive Inspector pentru notebook-uri - 800 de ruble.
Hard Drive Inspector este o soluție la îndemână pentru monitorizarea S.M.A.R.T. a HDD-urilor externe și interne. În prezent, programul este oferit pe piață în două ediții: Hard Drive Inspector Professional de bază și Hard Drive Inspector portabil pentru Notebook-uri; acesta din urmă include toate funcționalitățile versiunii Professional și, în același timp, ține cont de specificul monitorizării hard disk-urilor laptopurilor. Teoretic, există o altă versiune a SSD-ului, dar este distribuit doar în livrările OEM.
Programul oferă verificarea automată a atributelor SMART la intervale specificate și, la finalizare, își emite verdictul cu privire la starea unității, afișând valorile anumitor indicatori condiționali: „fiabilitate”, „performanță” și „fără erori” împreună cu o valoare numerică a temperaturii și o diagramă de temperatură. De asemenea, furnizează date tehnice despre modelul de unitate, capacitatea acestuia, spațiul liber total și timpul de funcționare în ore (zile). În modul avansat, puteți vizualiza informații despre parametrii discului (dimensiunea tamponului, numele firmware-ului etc.) și tabelul de atribute S.M.A.R.T. Există diverse opțiuni pentru informarea utilizatorului în cazul unor modificări critice pe disc. În plus, utilitarul poate fi folosit pentru a reduce nivelul de zgomot produs de hard disk-uri și pentru a reduce consumul de energie al HDD-ului.
HD Life 4.0
Dezvoltator: BinarySense Ltd.
Mărimea distribuției: 8,45 MB
Munca sub control: Windows 2000/XP/2003/Vista/7/8
Metoda de distribuire: shareware (demo de 15 zile - http://hddlife.ru/rus/downloads.html)
Preț: HDDlife - gratuit; HDDLife Pro - 300 de ruble; HDDlife pentru notebook-uri - 500 de ruble.
HDDLife este un utilitar simplu conceput pentru a monitoriza starea hard disk-urilor și a SSD-urilor (începând cu versiunea 4.0). Programul este prezentat în trei ediții: HDDLife gratuit și două ediții comerciale - HDDLife de bază Pro și HDDlife portabil pentru Notebook-uri.
Utilitarul monitorizează atributele SMART și temperatura la intervale specificate și, pe baza rezultatelor analizei, emite un raport de stare a discului compact care indică date tehnice despre modelul și capacitatea discului, orele lucrate, temperatura și, de asemenea, afișează procentul condiționat al stării sale. și performanță, care permite navigarea în situație chiar și pentru începători. Utilizatorii mai experimentați se pot uita în plus la tabelul atributelor S.M.A.R.T. În cazul unor probleme cu hard disk-ul, este posibilă configurarea notificărilor; puteți configura programul astfel încât atunci când discul este într-o stare normală, rezultatele verificării să nu fie afișate. Nivelul de zgomot HDD și consumul de energie pot fi controlate.
CrystalDiskInfo 5.4.2
Dezvoltator: Hiyohiyo
Mărimea distribuției: 1,79 MB
Munca sub control: Windows XP/2003/Vista/2008/7/8/2012
Metoda de distribuire: software gratuit (http://crystalmark.info/download/index-e.html)
Preț: este gratuit
CrystalDiskInfo este un utilitar simplu pentru monitorizarea stării S.M.A.R.T. a hard disk-urilor (inclusiv a multor HDD-uri externe) și a SSD-urilor. În ciuda programului gratuit, programul are toate funcționalitățile necesare pentru a organiza monitorizarea sănătății discului.
Discurile sunt monitorizate automat după un anumit număr de minute sau la cerere. La sfârșitul testului, tava de sistem afișează temperatura dispozitivelor monitorizate; Informații detaliate despre HDD-ul cu valorile S.M.A.R.T., temperatură și verdictul programului asupra stării dispozitivelor sunt disponibile în fereastra principală a utilitarului. Există o funcționalitate pentru a seta valori de prag pentru unii parametri și pentru a notifica automat utilizatorul dacă acestea sunt depășite. Sunt posibile managementul nivelului de zgomot (AAM) și managementul puterii (APM).
Din păcate, o mare parte din HDD-urile moderne funcționează în mod normal puțin peste un an, apoi încep tot felul de probleme, care în timp pot duce la pierderea datelor. O astfel de perspectivă poate fi complet evitată dacă monitorizați cu atenție starea hard disk-ului, de exemplu, folosind utilitățile discutate în articol. Cu toate acestea, nu trebuie să uitați nici de backup-ul regulat al datelor valoroase, deoarece utilitățile de monitorizare, de regulă, prezic cu succes defecțiunea unui disc din vina „mecanicii” (conform statisticilor Seagate, aproximativ 60% dintre HDD-uri eșuează din cauza componentelor mecanice), dar nu sunt capabili să prezică moartea unității din cauza problemelor cu componentele electronice ale unității.
05. 08.2017
Blogul lui Dmitri Vassiyarov.
Citiri SMART HDD - ce este și de ce?
Bună prieteni. Ați dori să priviți în viitor și să aflați când se va eșua hard disk-ul computerului dvs.? Acest lucru este posibil și datorită nu ghicitorilor, ci oamenilor de știință care au dezvoltat tehnologia SMART HDD. Acum, discul va fi sub controlul tău apropiat.
Este extrem de important să monitorizați starea acestuia, deoarece hard disk-ul, de regulă, stochează informații care se acumulează de ani de zile. Există cazuri frecvente în care un hard disk se defectează brusc pentru proprietarul său și este imposibil să recuperați fișierele.
Pentru a preveni acest lucru, consultați acest articol. Veți afla ce este SMART, cine îl poate folosi, cum să o faceți și o mulțime de informații utile în plus.
Debriefing
Cei care sunt cel puțin puțin familiarizați cu limba engleză pot crede că tehnologia se numește SMART pentru că este „inteligentă”. În acest caz, o astfel de traducere nu este adecvată.
Aceasta este o abreviere, a cărei decodare sună ca „tehnologie de auto-monitorizare, analiză și raportare”, ceea ce înseamnă „tehnologie de auto-monitorizare, analiză și raportare”.
Din aceasta, puteți trage o concluzie despre scopul său în ceea ce privește hard disk-urile. Dar tehnologia nu este implementată în fiecare dintre ele, ci doar în cele care acceptă protocolul SATA. În general, toate acestea sunt modele moderne.

Istoria apariției
Primul hard disk cu această tehnologie a fost lansat în 1992 de IBM. Sistemul avea mult mai puține funcționalități, dar ideea era bună. Prin urmare, Seagate, Quantum, Conner și Compaq și-au dezvoltat propria tehnologie similară.
Pe viitor, ultima companie de pe această listă și-a propus standardizarea produsului, drept urmare toate mărcile listate, împreună cu Western Digital, au introdus în lume tehnologia SMART HDD.
Prima versiune prevedea analiza parametrilor principali ai hard disk-urilor și a intrat în acțiune doar la comandă. Hitachi a participat și la dezvoltarea celei de-a doua generații, depunând ideea de introspecție HDD. SMART 3 adaugă opțiunea de a detecta defectele și de a le remedia.
Ce poate face SMART?
Am atins deja acest subiect puțin mai sus, acum ne vom opri mai detaliat asupra lui. Folosind această tehnologie, puteți diagnostica starea curentă a unității. Rezultatele testului vă vor arăta:
- Numărul de sectoare realocate;
- Urmărește viteza de căutare;
- Numărul de cicluri de pornire și oprire;
- Numărul de erori generate în acest caz și multe altele.
O altă opțiune SMART utilă este înlocuirea automată a sectoarelor care nu pot fi citite. Ea le introduce în jurnalul de erori, așa-numitele. masa.
Cu fiecare scanare, aceste celule sunt reverificate. Dacă se dovedesc a fi reparabile, sistemul le exclude din listă, dacă nu, le mută pe o altă listă de defecte, după care sectoarele nu mai sunt folosite.
Pe lângă monitorizarea componentelor sistemului, SMART hdd evaluează și starea fizică a hard disk-ului și, prin urmare, este capabil să prezică momentul defecțiunii acestuia. Poti sa vezi:
- De câte ori s-a mișcat capul și s-a întors axul;
- La ce înălțime se află capul deasupra suprafeței hard disk-ului etc.
Astfel, dacă vreunul dintre parametrii fizici nu corespunde normei, tehnologia te va anunța despre asta.
Dar rețineți că nu poate asigura deteriorarea hard disk-ului din cauza supratensiunii sau șocurilor.

Software-ul necesar
Pentru ca SMART hdd să funcționeze, nu este suficient doar să ai un hard disk care să-l suporte. În plus, trebuie să instalați un program special prin care veți comunica cu software-ul încorporat în controlerul hard diskului.
Puteți obține datele, dar va fi dificil de decriptat. Și în aceste scopuri, aveți nevoie de software special. Cum să vizualizați rezultatele testelor? Aici sunt cateva exemple:
Victoria.
Despre ea am deja. Una dintre cele mai populare opțiuni pentru care nu trebuie să plătiți. După pornirea utilitarului, trebuie să selectați șurubul pentru a verifica în fila Standard, comutați la meniul Smart și faceți clic pe butonul Obțineți. Starea de sănătate a HDD-ului dvs. va fi afișată prin indicatori de nivel și culoare.

Iată linkul oficial: //crystalmark.info/redirect.php?product=CrystalDiskInfoInstaller
Una dintre cele mai convenabile și, de asemenea, gratuite modalități de a explora șurubul, deoarece interfața este simplă și puteți schimba limba în rusă. Selectați un disc din fila cu același nume din partea de sus, iar toți parametrii acestuia se vor desfășura în fața dvs. de mai jos. 
Apropo, deja în Windows 7, suportul SMART HDD este implementat în snap-in-ul Computer Management. În special, Disk Check este principalul colector de informații despre starea sistemului.

Descifrarea rezultatelor
Sistemul stochează informații în formă hexazecimală, denumită valoare brută („valori brute”). Datele sunt formatate în parametrul valoare, care afișează fiabilitatea hard disk-ului în conformitate cu standardul.
Evaluarea se face în principal pe o scară de la 0 la 100, dar unele elemente sunt măsurate în intervalul de la 0 la 253. Un număr mare indică o stare normală, iar unul scăzut indică posibilitatea unei defecțiuni iminente. Dacă rezultatul este mai mic decât minimul la care producătorul elicei își garantează funcționarea fără probleme, atunci ansamblul este defect.
Cu ce seamănă?
Programul afișează rezultatele sub forma unui tabel împărțit în mai multe câmpuri obligatorii:
- ID (Num) - numărul de identificare al parametrului;
- Nume - descrierea acestuia;
- VAL - un număr care indică starea discului (după cum s-a menționat mai sus);
- Wrst (Worst) - cea mai proastă valoare din istoria hardului tău;
- Thresh (Threshold) - numărul până la care șurubul va eșua.

Atribute SMART
În lista „Nume” veți găsi multe atribute, fiecare dintre acestea fiind responsabilă pentru un anumit parametru dur. Toate sunt lungi și inutile de enumerat. Luați în considerare la ce să acordați atenție în principal:
- (5) Număr de sector realocat. Afișează numărul de sloturi remapate de pe HDD.
- (7) Seek Error Rate. Aici puteți afla cât de des eșuează poziționarea unității de cap magnetic (HMG).
- (11) Încercări de recalibrare. Returnează numărul de încercări de calibrare a HMG care a eșuat.
- (184) Eroare de la capăt la capăt. Indică numărul de erori din memoria tampon de unitate.
- (187) Eroare necorecabilă raportată. Câte erori nu a putut remedia firmware-ul dispozitivului.
- (191) Rata de eroare G-Sense. Indică de câte ori s-a defectat elicea din cauza impactului. Parametrul este determinat de accelerometrul intern.
- (197) Număr curent de sector în așteptare. Afișează sectoare instabile care ar putea înceta să funcționeze în curând.
- (198) Număr de sector incorectabil. Se traduce ca contor de erori necorectabile.
- (199) Număr de erori UltraDMA CRC. Contorizează eșecurile care au apărut în timpul transferului de date de pe disc pe computer. Dacă numărul acestora crește, cablul trebuie înlocuit.
Apropo, sistemul detectează adesea sectoare proaste nu din cauza învechirii hard disk-ului, ci din cauza unei întreruperi bruște de curent sau a unui defect al cablului. Dar, de fapt, aceste blocuri sunt destul de eficiente. În astfel de cazuri, puteți reseta atributele, dar acest proces este cel mai bine lăsat specialiștilor.
Opțiuni de testare
Sistemul SMART poate efectua mai multe tipuri de teste:
- Scurt (Scurt). Durează aproximativ 2 minute. Sunt efectuate verificări electrice, mecanice și performanțe de citire.
- Lung / extins (Lung / extins). Timp de livrare: 2-3 ore. Se evaluează suprafața hard disk-ului.
- Selectiv. Este necesar pentru studiul componentelor individuale ale unității.
- Test de transport. Nu durează mult. Este necesar să se analizeze starea dispozitivului după transportul de la furnizor la utilizator.
Asta e tot.
Lăsați rezultatele testelor dvs. să fie pozitive.